本文摘自笔记:http://ai-start.com/ml2014/html/week8.html
参考视频: 13 – 2 – K-Means Algorithm (13 min).mkv
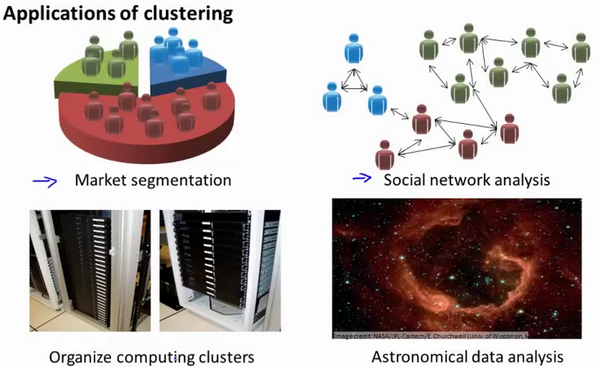
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
1)算法的基本过程
K-均值是一个迭代算法,假设我们想要将数据聚类成n个组,其方法为:
- 首先选择 K 个随机的点,称为聚类中心(cluster centroids)
- 对于数据集中的每一个数据,按照距离 K 个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类
- 计算每一个组的平均值
- 将该组所关联的中心点移动到平均值的位置
重复步骤2-4直至中心点不再变化