论文:https://www.pdl.cmu.edu/ftp/NVM/tmo_asplos22.pdf
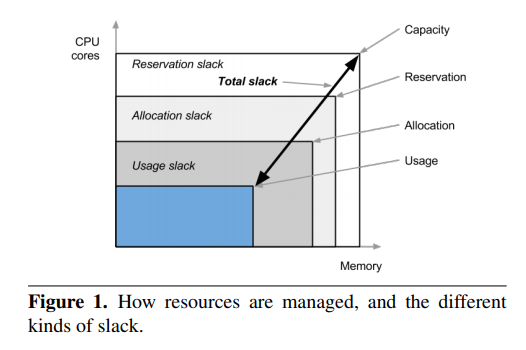
内存是数据中心最大的瓶颈。百度也是如此,因为内存不足,导致大量机器cpu空闲但是利用率无法提升的主要原因
这篇论文的思路和 google 的 software-defined far memory 思路几乎是一样的,都是把 colder memory 卸载到 cheaper memory 上
google 论文是19年发表的,实际上项目2016年就已经上线了
facebook 论文是22年发表的,线上已经运行一年多。另外,论文里也隐约的提了,facebook就是在google的基础上做的,但是发现效果和 google 说的不一样,于是做了很多改进。如果我们要落地,也会有类似的问题。
1. INTRODUCTION
下文所有对比的地方,我简称:
- google的方案,g-swap
- facebook的方案,tmo
现状:
cpu的发展速度比memory要快
随着AI算法的发展,业务对内存的需求正在快速膨胀
硬件上,nvm和nvme ssd等技术的出现,Non-dram cheaper memory 开始越来越多的被使用
还有 CXL 这种 non-DDR memory bus 技术,可以接近 DDR 的原生性能
方向:内存分层技术,不管是 google 的 software-defined far memory 也有还是 facebook 的 TMO(透明内存卸载),本质上都是将低频访问的内存卸载到低速设备上
With memory tiering, less frequently accessed data is migrated to slower memory.
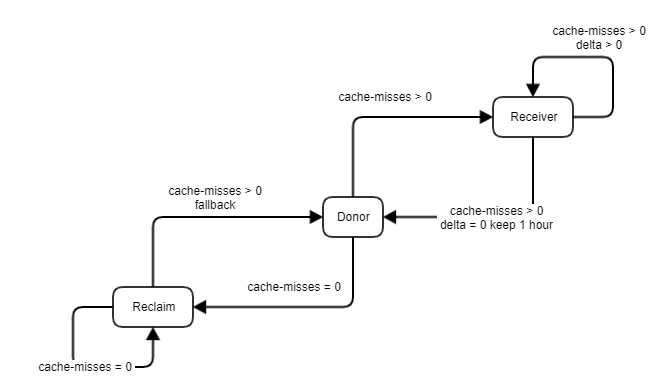
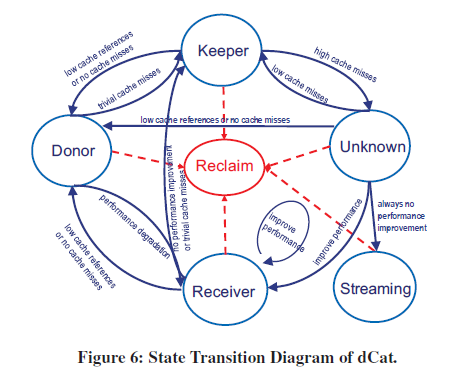
g-swap的一些问题:
- 核心是压缩
- 非常简单
- 好处:不用解决异构这些复杂的问题(感觉解决了?做了负载分类)
- 坏处:不利于最大化的 memory-cost saving
- promotion rate 的设定依赖离线分析
- 所有应用的 promotion rate 是一样的。没有考虑不同业务对内存的敏感性,以及不同分层设备的 performance(后者其实有简单的考虑,具体的 P% 的设备就取决于 far memory 到 near memory 的性能表现)
- g-swap的观点:为了保证应用程序的性能,memory offloading 应该控制在一个预先配置好的比例下面
- tmo的观点:facebook 对它们部署规模最大的程序,发现,在一些高速设备上,提高 memory offloading 比例,可以提高性能。 –> 反人类假设??

为了解决这些问题,facebook 提出了 tmo 方案,优点:
- 核心是卸载(但是卸载的backend 支持 compressed memory pool,也支持 NVMe SSDs)
- 不需要离线分析,依赖 PSI 的反馈,直接单机决定不同的 offloading 比例。不依赖app的任何先验知识(g-swap的方案就有一个冷启动问题,新app默认不回收任何内存)
- PSI accounts for application’s sensitivity to memory-access slowdown(这里其实是比较误导的,facebook认为psi观测出来的内存延迟一定是对业务敏感的,但是实际上不同的业务对延迟的敏感性是不一样的,简单来说这个是充分不必要条件)
收益空间:20-32% 收益,百万服务器,其中7-19%由应用贡献,13%由sidecar等基础服务贡献