https://yiyibooks.cn/arxiv/2310.05869v3/index.html

经验上,HyperAttention 表明了显著的加速,在n=131k 的序列长度的正向和反向传播中实现了超过50×的加速。在处理因果掩码时,该方法仍然提供了实质性的5×加速。
https://yiyibooks.cn/arxiv/2310.05869v3/index.html
经验上,HyperAttention 表明了显著的加速,在n=131k 的序列长度的正向和反向传播中实现了超过50×的加速。在处理因果掩码时,该方法仍然提供了实质性的5×加速。
https://arxiv.org/pdf/2311.18677
https://yiyibooks.cn/arxiv/2311.18677v2/index.html
论文的核心思想:不管是 Ocra、还是 ExeGPT、还是 SplitWise,论文都提到一些关键的特点,整个推理可以分为2部分,提示阶段(首token计算阶段)和词生成,这2个阶段的负载类型是截然不同的,对算力的要求也不一样,因此,通过拆分这2阶段的计算,未来资源池里面,一部分机器用来跑首 token 计算,一部分机器用来跑词生成,通过这个方式,整个推理的吞吐提升了2倍左右

由于编码服务的常见情况只需要在用户键入时在程序中生成接下来的几个单词,因此输出词符的中位数为 13 个标记。另一方面,对话服务几乎呈双峰分布,生成的 Token 中位数为 129 个。洞察1:不同的推理服务可能具有截然不同的token数量分布(提示阶段、词生成阶段)
batch size = 30,但不代表每时每刻都有 30 个请求在处理,实际情况有很多管道气泡 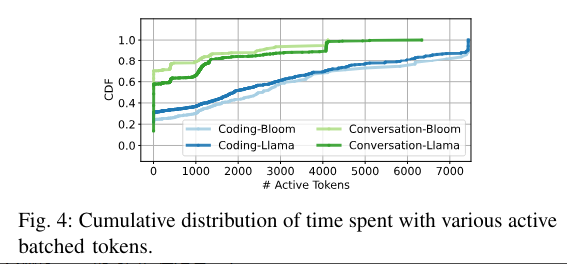
如果一个请求,在做词生成,那标记为1个活跃的token。上面这个图就是 GPU 活跃 token 数量的一个累计分布函数从这个图可以看出:
也就是说,GPU 实际运行过程中,是有非常多管道气泡的。比如 batch size 是 30,但是还是有很多时间,只有1个token在处理
推测:
Q:为什么会出现这个问题?
A:由于请求和 seq 长度存在一定的分布,所以必然会存在很多时刻,很多流水线是处于 “短暂” 的空闲的,这种空闲的时间片,就是管道气泡
Q:能不能通过缩小 Batch size 来降低管道气泡?
A:不能,因为缩小 Batch size 会推高长尾延迟,整体吞吐下降
Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache
模型的架构:
超长文推理的挑战,2k -> 256k ?
有2个:
这2个问题,最终也极大的限制了超长文推理的效果
https://mp.weixin.qq.com/s/uK1owRF53FW4WI7nldYadg
https://arxiv.org/pdf/2311.15566.pdf
业界首个,在可抢占式实例上运行的分布式大语言模型(LLM)服务系统
目标:LLM 降本 -> 抢占式 GPU 实例 -> 怎么更好的用这些抢占实例
相比直接使用抢占式GPU实例,SpotServe 可以将推理引擎的长尾延迟降低 2.4x – 9.1x
LLM 特点:
无论是哪一点,都意味着成本昂贵
把 LLM 运行在随时可抢占的 GPU 实例上
传统的方法,MArk、Cocktail,单实例多GPU卡,运行一个 small DNN 模型,通过请求重定向或者冗余计算来处理抢占,但是这种方式只是和数据并行这种小的DNN模型,不适合LLM
LLM 会同时使用数据并行、模型并行、流水线并行多种技术,单个实例抢占会影响整个多个实例的计算结果
所以需要有更有效的方法
亮点:第一个做推理容错的论文(其他的都是在做训练的容错)
SpotServe 的创新点:
当前类似的系统:
单次推理的总耗时,分析
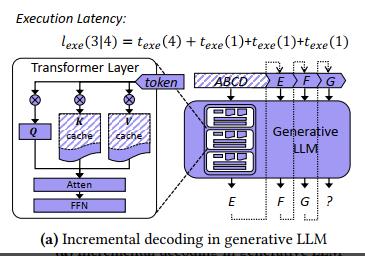
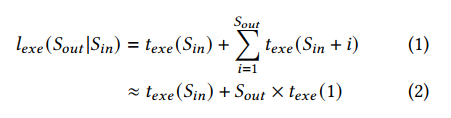
texe(Sin) 是输入序列的解码时间
Sout 是生成的 token 数量,texe(1) 是生成每个 token 的时间
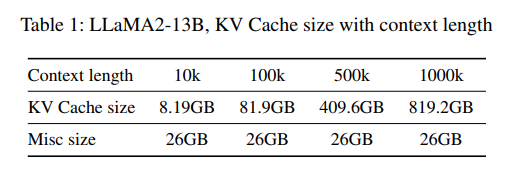
KV cache 技术可以将每个 token 的生成时间优化到接近常量 (i.e., 𝑡𝑒𝑥𝑒 (1) in E.q.(2) and Figure 1a).

@tvm.script.ir_module
class MyModule:
@T.prim_func
def main(a: T.handle, b: T.handle):
# 我们通过 T.handle 进行数据交换,类似于内存指针
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# 通过 handle 创建 Buffer
A = T.match_buffer(a, (8,), dtype="float32")
B = T.match_buffer(b, (8,), dtype="float32")
for i in range(8):
# block 是针对计算的抽象
with T.block("B"):
# 定义一个空间(可并行)block 迭代器,并且将它的值绑定成 i
vi = T.axis.spatial(8, i)
B[vi] = A[vi] + 1.0
ir_module = MyModule
from tvm import te
A = te.placeholder((8,), dtype="float32", name="A")
B = te.compute((8,), lambda *i: A(*i) + 1.0, name="B")
func = te.create_prim_func([A, B])
ir_module_from_te = IRModule({"main": func})
print(ir_module_from_te.script())
搞虚拟化的,经常会遇到很多和内核相关的线上问题。比如最近我们遇到一个 k8s 的 pod 在删除的时候 pvc 卸载不掉的情况。

umount 的时候提示挂载点已经 not mounted 了,但是在 /proc/mounts 里仍然存在。statvfs 看了一下,这个挂载点的device id和父目录的device id 是一样的,说明已经不是挂载点了(因为看 /proc/mounts,这个挂载点的src是在另外一个设备上)
特别注意:如果 /proc/mounts 里,src 和 dst 是同一个设备,那就是 –bind 的方式,这种情况下就很难判断挂载点是否已经真正的卸载掉了
针对这个问题,社区已经有了一个比较 hack 的解决方案:https://github.com/kubernetes/kubernetes/issues/114546,就是忽略 /proc/mounts 残留,允许 pod 删除流程继续往下走
但是根源还是内核的存在脏数据(大概率猜测可能是引用计数泄露导致),还是得从内核层面定位这种问题,而且这种问题,很多时候我们得知道内核代码的执行路径是什么样的。这个时候用 ftrace 来定位就很方便了,比 eBPF 好使,ftrace 能够直接跟踪一个内核函数的调用栈

|
broadcast
|
elemwise
|
nn
|
reduction
|
|
topi.add
topi.subtract
topi.multiply
topi.divide
topi.floor_divide
topi.mod
topi.floor_mod
topi.maximum
topi.minimum
topi.power
topi.left_shift
topi.logical_and
topi.logical_or
topi.logical_xor
topi.bitwise_and
topi.bitwise_or
topi.bitwise_xor
topi.right_shift
topi.greater
topi.less
topi.equal
topi.not_equal
topi.greater_equal
topi.less_equal
topi.broadcast_to
|
topi.acos
topi.acosh
topi.asin
topi.asinh
topi.atanh
topi.exp
topi.fast_exp
topi.erf
topi.fast_erf
topi.tan
topi.cos
topi.cosh
topi.sin
topi.sinh
topi.tanh
topi.fast_tanh
topi.atan
topi.sigmoid
topi.sqrt
topi.rsqrt
topi.log
topi.log2
topi.log10
topi.identity
topi.negative
topi.clip
topi.cast
topi.reinterpret
topi.elemwise_sum
topi.sign
topi.full
topi.full_like
topi.logical_not
topi.bitwise_not
|
topi.nn.relu
topi.nn.leaky_relu
topi.nn.prelu
topi.nn.pad
topi.nn.space_to_batch_nd
topi.nn.batch_to_space_nd
topi.nn.nll_loss
topi.nn.dense
topi.nn.bias_add
topi.nn.dilate
topi.nn.flatten
topi.nn.scale_shift_nchw
topi.nn.scale_shift_nhwc
topi.nn.pool_grad
topi.nn.global_pool
topi.nn.adaptive_pool
topi.nn.adaptive_pool3d
topi.nn.pool1d
topi.nn.pool2d
topi.nn.pool3d
topi.nn.softmax
topi.nn.log_softmax
topi.nn.lrn
topi.nn.binarize_pack
topi.nn.binary_dense
|
topi.sum
topi.min
topi.max
topi.argmin
topi.argmax
topi.prod
topi.all
topi.any
|
a1 = relay.var("a1", shape=(1,), dtype="float32")
c1 = relay.const(10, 'float32')
c2 = relay.add(c1, a1)
i = 320 * 200 * 32;

int x = 14; int y = 7 - x / 2; return y * (28 / x + 2); //常量传播 int x = 14; int y = 7 - 14 / 2; return y * (28 / 14 + 2); //常量折叠 int x = 14; int y = 0; return 0;