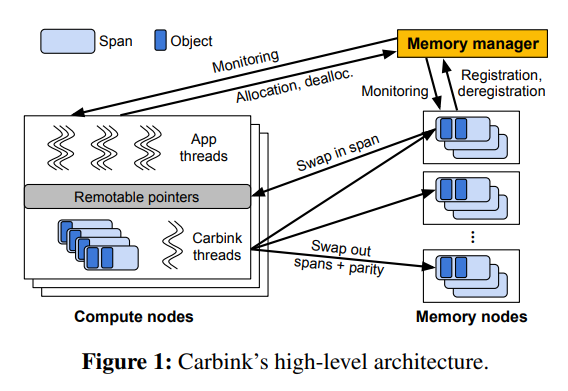
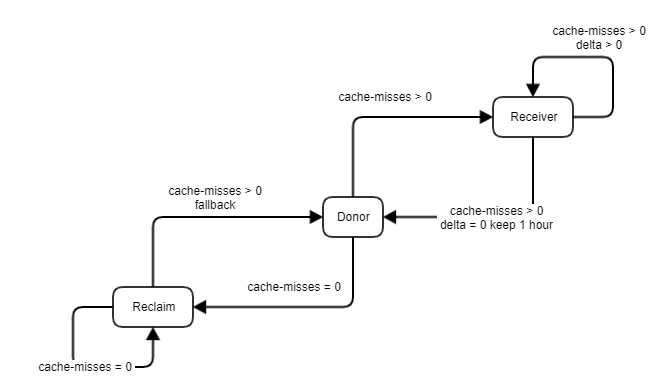
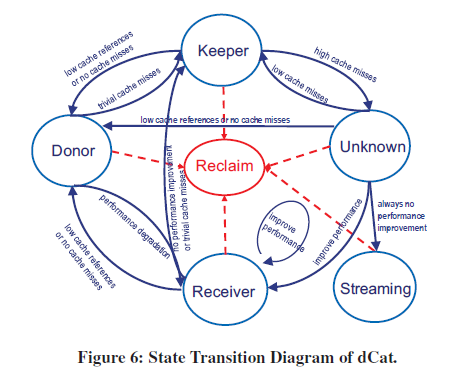
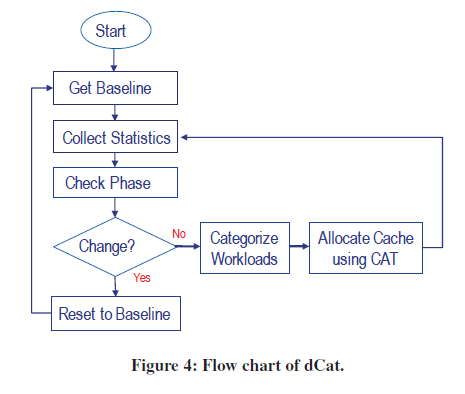
核心前提:只要独占 cache size 足够大,业务的性能是可以得到保证的
we can conclude that whether CAT can provide perfor mance isolation between workloads is highly dependent on the size of the dedicated cache
baseline是基准性能,但是每个阶段,都有不同的 baseline,会动态变化 Baseline performance is only defined for a specifi workload phase, so it has to be determined again at every phase change.