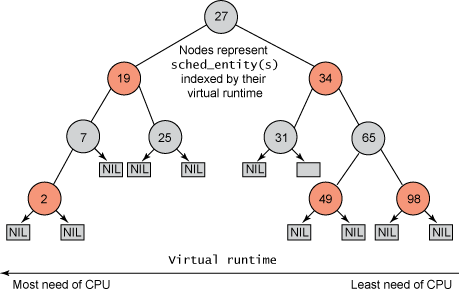
cgroup_mutex 是内核实现 cgroup 子系统而重度依赖的一把全局锁,这把全局锁在很多场景下会带来非常多的性能问题。具体这里不展开讲了,google 一下 cgroup_mutex deadlock,可以看到一堆 bugs report
最近线上恰好遇到一次机器死机的场景,后来分析发现和 cgroup_mutex 死锁有关(严格来说不叫死锁,叫夯死更合适一些),以此记录分析过程
1. 现象
机器存在大量的 D 进程,监控发现系统负载缓慢持续增高,应该是由于D进程持续不断地堆积,导致负载越来越高
所有与 cgroup_mutex 打交道的地方,都会卡死,比如简单来说 cat /proc/self/cgroup 会立即进入夯死状态,进程无法 kill -9 杀掉
我们通过一些艰难的内核栈跟踪,终于捕捉到了内核临死前的锁持有的状态(此处省略掉1万字跟踪过程)
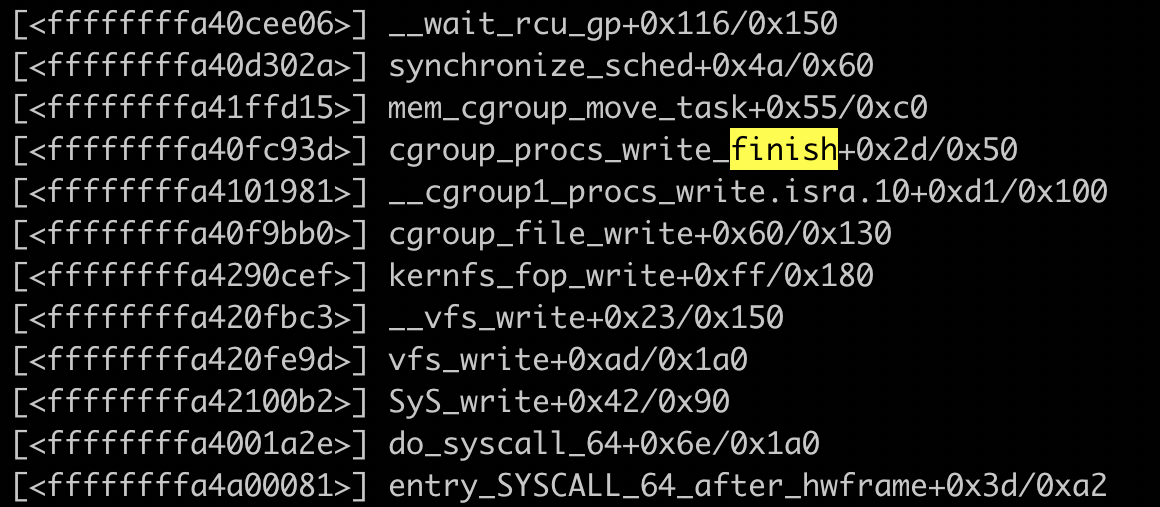
2. 内核栈分析
读过内核源码或者了解内核原理的应该知道,vfs_write 是内核文件系统的抽象层。vfs_write 接着调用 cgroup_file_write,这个说明当前进程正在写 cgroup 文件系统,然后在写过程中,陷入 synchronize_sched,进程被换出,然后应该是一直卡在这里了。
但是真正导致系统死机的,并不是 synchronize_sched 这个地方,二是一个很复杂的链,触发场景:
- 进程持有 cgroup_mutex
- 进程尝试获取其他锁,或者进入睡眠态
- 进程 cfs 时间片被 throt,导致进程无法重新获得 cpu 的控制权,cgroup_mutex 无法释放
cgroup_mutex 是一把极大的锁,几乎任何 cgroup 操作都会涉及到这把锁的操作。在我们这个场景里,进程持有 cgroup_mutex 之后陷入 __wait_rcu,其他进程在尝试持有 cgroup_mutex 的时候几乎全部都夯住了