cgroup_mutex 是内核实现 cgroup 子系统而重度依赖的一把全局锁,这把全局锁在很多场景下会带来非常多的性能问题。具体这里不展开讲了,google 一下 cgroup_mutex deadlock,可以看到一堆 bugs report
最近线上恰好遇到一次机器死机的场景,后来分析发现和 cgroup_mutex 死锁有关(严格来说不叫死锁,叫夯死更合适一些),以此记录分析过程
1. 现象
机器存在大量的 D 进程,监控发现系统负载缓慢持续增高,应该是由于D进程持续不断地堆积,导致负载越来越高
所有与 cgroup_mutex 打交道的地方,都会卡死,比如简单来说 cat /proc/self/cgroup 会立即进入夯死状态,进程无法 kill -9 杀掉
我们通过一些艰难的内核栈跟踪,终于捕捉到了内核临死前的锁持有的状态(此处省略掉1万字跟踪过程)
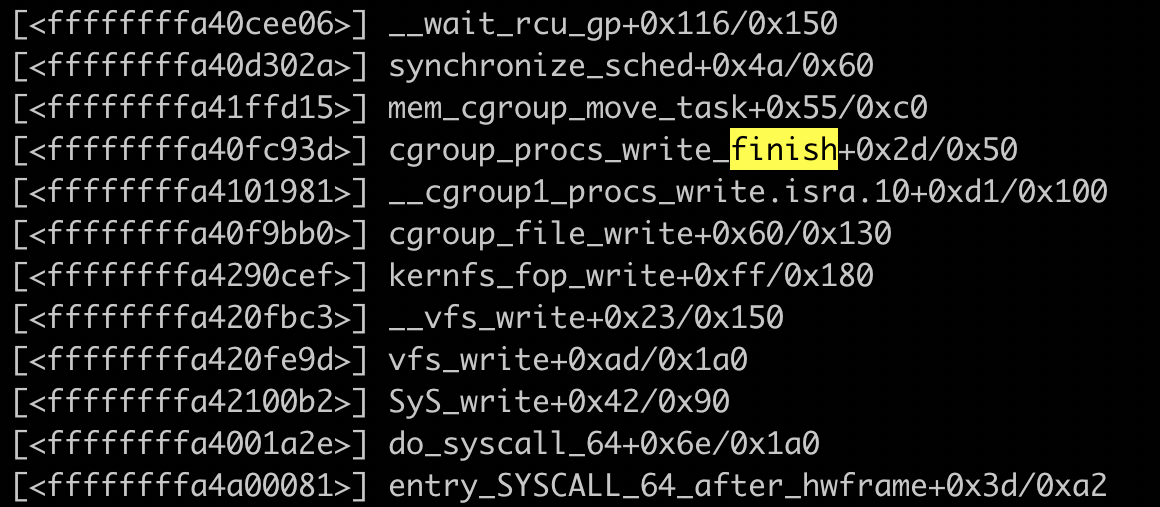
2. 内核栈分析
读过内核源码或者了解内核原理的应该知道,vfs_write 是内核文件系统的抽象层。vfs_write 接着调用 cgroup_file_write,这个说明当前进程正在写 cgroup 文件系统,然后在写过程中,陷入 synchronize_sched,进程被换出,然后应该是一直卡在这里了。
但是真正导致系统死机的,并不是 synchronize_sched 这个地方,二是一个很复杂的链,触发场景:
- 进程持有 cgroup_mutex
- 进程尝试获取其他锁,或者进入睡眠态
- 进程 cfs 时间片被 throt,导致进程无法重新获得 cpu 的控制权,cgroup_mutex 无法释放
cgroup_mutex 是一把极大的锁,几乎任何 cgroup 操作都会涉及到这把锁的操作。在我们这个场景里,进程持有 cgroup_mutex 之后陷入 __wait_rcu,其他进程在尝试持有 cgroup_mutex 的时候几乎全部都夯住了
我们通过内核代码,来回顾一下整个过程:
1)首先是进程修改 cgroup 文件系统
vfs_write 是内核文件系统抽象层的接口,我们直接看 cgroup_file_write 即可,不同的文件系统,有不同的 ->write() 函数实现,既然我们操作的是 cgroup 文件系统,当然入口函数是 cgroup_file_write 了
static struct kernfs_ops cgroup_kf_ops = {
.open = cgroup_file_open,
.release = cgroup_file_release,
.write = cgroup_file_write,
......
};
static ssize_t cgroup_file_write(struct kernfs_open_file *of, char *buf,
size_t nbytes, loff_t off)
{
......
if (cft->write)
return cft->write(of, buf, nbytes, off);
......
if (cft->write_u64) {
unsigned long long v;
ret = kstrtoull(buf, 0, &v);
if (!ret)
ret = cft->write_u64(css, cft, v);
} else if (cft->write_s64) {
long long v;
ret = kstrtoll(buf, 0, &v);
if (!ret)
ret = cft->write_s64(css, cft, v);
}
......
}
我们知道 cgroup 有很多子系统,比如 cpu、memory、io,不同的 cgroup 子系统又会有不同的 write 实现方式,比如 memory 的 write 操作会触发内存回收,比如 cpuset 的 write 操作,会触发 domain balance。甚至同一个子系统下,不同的cgroup接口,都有不同的 write 实现,比如 memory 子系统,memory.drop_cache 和 memory.limit_in_bytes 对应的内核实现显然是不一样的
我们从上面的 mem_cgroup_move_task() 可以看出当前正在操作的是内存子系统。从内核代码分析来看,mem_cgroup_move_task() 函数是 memory_cgrp_subsys 的 post_attach 接口实现,只有在写 cgroup.procs 接口时触发的
void cgroup_procs_write_finish(struct task_struct *task)
__releases(&cgroup_threadgroup_rwsem)
{
struct cgroup_subsys *ss;
int ssid;
/* release reference from cgroup_procs_write_start() */
put_task_struct(task);
percpu_up_write(&cgroup_threadgroup_rwsem);
for_each_subsys(ss, ssid)
if (ss->post_attach)
ss->post_attach();
}
struct cgroup_subsys memory_cgrp_subsys = {
.css_alloc = mem_cgroup_css_alloc,
.css_released = mem_cgroup_css_released,
.can_attach = mem_cgroup_can_attach,
.post_attach = mem_cgroup_move_task,
.bind = mem_cgroup_bind,
......
};再来看下 mem_cgroup_move_task() 函数的实现,mem_cgroup_move_task会调用 mem_cgroup_move_charge 来迁移不同 cgroup 之间的计数。比如当你把一个进程的 pid,从一个 cgroup 迁移到另外一个 cgroup 的时候,这个 pid 在原 cgroup 里面的内存使用,会迁移到目标 cgroup
mem_cgroup_move_charge() 里面会调用 synchronize_rcu,也就是最终会调到 synchronize_sched 里面
static inline void synchronize_rcu(void)
{
synchronize_sched();
}
static void mem_cgroup_move_charge(void)
{
struct mm_walk mem_cgroup_move_charge_walk = {
.pmd_entry = mem_cgroup_move_charge_pte_range,
.mm = mc.mm,
};
lru_add_drain_all();
/*
* Signal lock_page_memcg() to take the memcg's move_lock
* while we're moving its pages to another memcg. Then wait
* for already started RCU-only updates to finish.
*/
atomic_inc(&mc.from->moving_account);
synchronize_rcu();
retry:
......
atomic_dec(&mc.from->moving_account);
}到目前为止,整个调用栈的过程就基本清楚了
3. 其他隐患
首先这个问题非常不好解,我们尝试在用户态针对内核实现做了一些规避方案,但是最终效果不理想。极端情况下 cfs 硬限会概率性引发 cgroup_mutex 死锁
除了写 memory 子系统的 cgroup.procs 接口会导致这个问题之外,我们还发现写 cpuset.procs 接口也会引发同样的问题,因为 cpuset 变更会触发内核进程的 domain balance,这个地方有同样的风险