使用 nsys & ncu 来分析 vllm 性能
大模型这么火,但却发现网上很少有相关的性能分析的资料,绝大部分都是偏理论的性能分析
最近发现了 nvidia 有很好的性能分析工具,nsys 和 ncu,于是决定用来研究下 vllm 的 decode 性能,本文将是一些记录,方便大家更好的学习和使用
1. nsys & ncu 基础
1.1. 简介
在之前的CUDA版本中,所附带的性能分析工具主要是nvvp(NVIDIA Visual Profiler)和nvprof,前者是带有图形界面的分析工具,后者是命令行工具。在CUDA官方文档中有这样一段描述:
Note that Visual Profiler and nvprof will be deprecated in a future CUDA release. The NVIDIA Volta platform is the last architecture on which these tools are fully supported. It is recommended to use next-generation toolsNVIDIA Nsight Systemsfor GPU and CPU sampling and tracing andNVIDIA Nsight Computefor GPU kernel profiling.
所以nvvp与nvprof现在已经废弃了,现在nvidia主要的性能分析工具就是nsys(Nsight System)和ncu(Nsight Compute)。
nsys是系统层面的分析工具,nsys 主要用来分析函数热点 ,产生类似于火焰图之类的数据。
ncu 则是用于分析一个具体的核函数 ,更多的是看核函数执行过程中 GPU 硬件的性能,比如内存带宽和 SM 利用率等等。
两者均有图形界面版本和命令行版本。这2个工具一般都是组合起来一起使用的
1.2. 安装
需要用邮箱注册一下,然后下载:
ncu:https://developer.nvidia.com/tools-overview/nsight-compute/get-started
nsys:https://developer.nvidia.com/nsight-systems/get-started
需要下载 deb 包和 msi 安装包前者安装在容器镜像里面,用于采集 Profile 数据后者安装在 windows 笔记本上(如果你是 mac,就装 mac 版就行),用于分析 Profile 数据比如我在容器里安装的就是:
NsightSystems-linux-cli-public-2024.6.1.90-3490548.deb
nsight-compute-linux-2024.3.2.3-34861637.run
1.3. 基本用法
nsys:
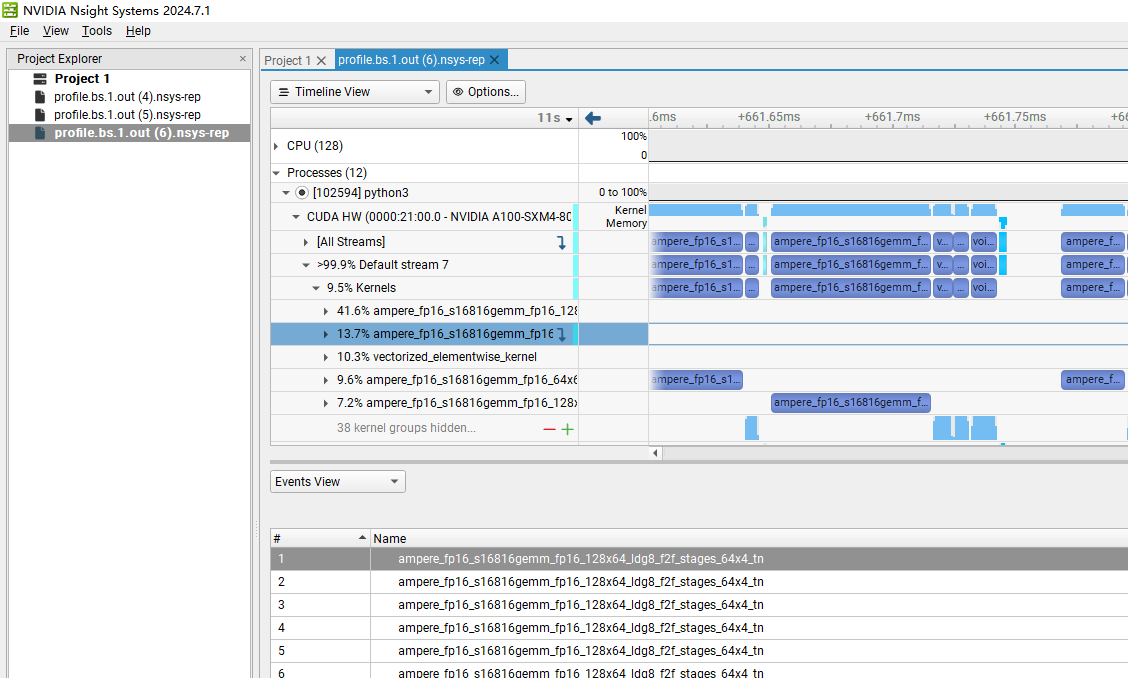
nsys profile -o /tmp/profile.out -f true python3 vllm_offline.py
运行结束会产生一个 profile.out.nsys-rep 文件
用 windows 打开就得到