第一次看 ng 斯坦福机器学习这门课程的时候,就没看懂交叉验证是怎么回事。
1. 模型选择和交叉验证集
参考视频: 10 – 3 – Model Selection and Train_Validation_Test Sets (12 min).mkv
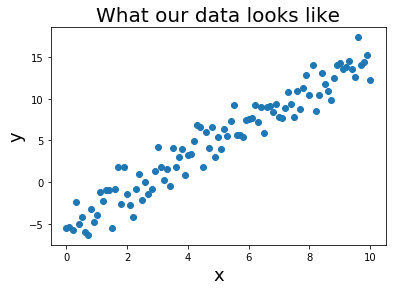
ng 在讲交叉验证的时候,是这么举例的
假设我们要在10个不同次数的二项式模型之间进行选择:
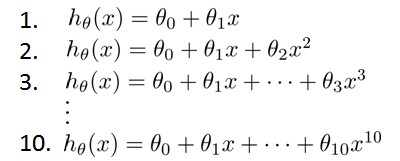
显然越高次数的多项式模型越能够适应我们的训练数据集,但是适应训练数据集并不代表着能推广至一般情况,我们应该选择一个更能适应一般情况的模型。我们需要使用交叉验证集来帮助选择模型。 即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集