第一次看 ng 斯坦福机器学习这门课程的时候,就没看懂交叉验证是怎么回事。
1. 模型选择和交叉验证集
参考视频: 10 – 3 – Model Selection and Train_Validation_Test Sets (12 min).mkv
ng 在讲交叉验证的时候,是这么举例的
假设我们要在10个不同次数的二项式模型之间进行选择:
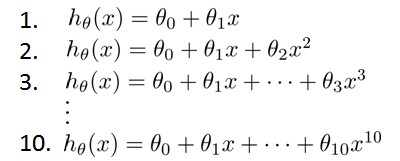
显然越高次数的多项式模型越能够适应我们的训练数据集,但是适应训练数据集并不代表着能推广至一般情况,我们应该选择一个更能适应一般情况的模型。我们需要使用交叉验证集来帮助选择模型。 即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集
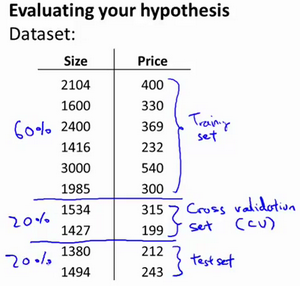
模型选择的方法为:
- 使用训练集训练出10个模型
- 用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
- 选取代价函数值最小的模型
- 用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)Train/validation/test errorTraining error
这个例子看起来比较简单,但是实操起来还比较麻烦的。因为计算交叉验证误差,并不是说,我们在训练神经网络的时候,直接简单的把数据集划分为3等份,然后用 training set 来训练神经网络,训练完用 cross validation set 来计算交叉验证的误差。如果你真的这么做了,说明你还没理解交叉验证
试想一下,如果真的这么简单,交叉验证误差有啥用呢?因为训练神经网络的过程中,就是求可以使得 training set 最小的参数集,然后选择模型的时候,选取交叉验证误差最小的模型。既然这样,为什么不直接把交叉验证集放到训练集里面就玩了?
2. k 折交叉验证法
关于三类数据集之间的关系,知乎上有一个非常恰当的解释
(1) 训练集相当于课后的练习题,用于日常的知识巩固。
(2) 验证集相当于周考,用来纠正和强化学到的知识。
(3) 测试集相当于期末考试,用来最终评估学习效果。
但是光有这个解释是不够的,不足以让我们理解为什么需要有交叉验证集。还得讲讲交叉验证的过程。关于这一点,西瓜书就有一个很好的例子说明
简单来说,交叉验证的具体步骤如下:
- 将数据集分为训练集和测试集,将测试集放在一边
- 将训练集分为 k 份
- 每次使用 k 份中的 1 份作为验证集,其他全部作为训练集。
- 通过 k 次训练后,我们得到了 k 个不同的模型。
- 评估 k 个模型的效果,从中挑选效果最好的超参数
- 使用最优的超参数,然后将 k 份数据全部作为训练集重新训练模型,得到最终模型。