调度单元有三种状态:
- 睡眠:不在 CPU 运行队列里
- PENDING:调度单元被唤醒,比如网络数据包到达,IO ready等,进程被唤醒,进入运行队列,但是还没得到 CPU 时间片
- 运行:调度单元得到 CPU 控制权,开始运行
调度延时其实就是指进程被唤醒,进入运行队列到得到 CPU 时间片之间的等待时间,也就是处于 PENDING 状态的时间
Linux 通过一个红黑树来维护所有进程的状态,每个 CPU 都会有一个运行队列,管理所有进程和进程组【注意,进程组也是内核的一个基本的调度单元】
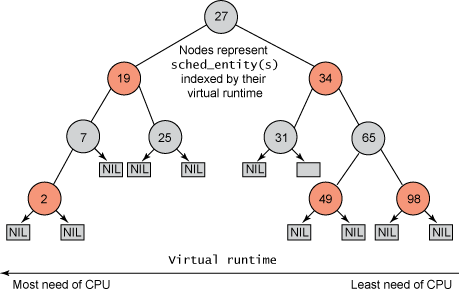
每个调度单元都会有一个 vruntime 的属性,用来记录当前调度单元以运行的虚拟时间
为了简化问题,我们只考虑单个 CPU 上的运行队列的调度逻辑,跨 CPU 还涉及时间片重算等更复杂的逻辑,暂不描述
CFS 调度的基本如下:
- 从 CPU 运行队列选择一个 vruntime 最小的进程 → 公平性原则,目的是要确保所有进程都尽可能的得到调度
- 进程运行完毕之后,更新vruntime,重新放入运行队列里等待下次被调度
CFS 为了实现完全公平的目的,在很多场景下,都牺牲了优先级
1. 最小时间片
CFS 有一个调度周期的概念,公平的要义在于:在一个调度周期内,确保每个调度单元都能得到调度的机会
假设一个 CPU 运行队列里有两个进程 P1和P2,假设 P1和P2 都是 CPU-bound 进程,那么各自都能得到 12ms 的运行时间
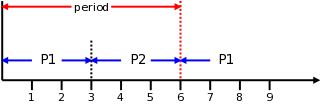
如果再多一个进程 P3,那每个周期内,每个进程只能拿到4ms的时间片
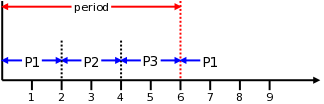
再多一个进程的时候是这个样子的
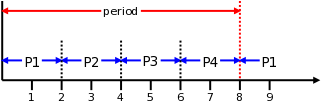
但是时间片不可能会按照进程数无限的切分下去,内核有一个最小值,一旦小于这个值,时间周期就会被延长,确保每个进程都能得到一次调度的机会
也就是说,调度周期是这么决定的
period = max(sched_latency_ns, sched_min_granularity_ns * nr_tasks)
sched_latency_ns 当前我们服务器默认是24ms
sched_min_granularity_ns 默认是4ms
你可以想象,假如一个 CPU 上跑了1000多个进程,其中只有一个高优先级的进程,最坏情况下,高优先级进程可能得等 999 * 4ms = 4s 才能得到下一次调度的机会
实际情况可能远没有这么夸张,但是也相当夸张,调度延时在100ms级别是非常常见的
实际情况没有这么夸张的几个原因:
- 调度域非常大,容器进程都分散到所有 CPU 上面去了,机器利用率不高,风险降低了很多
- 进程绝大部分都不会执行完一个时间片,因为各种 IO 操作,sleep 系统调用,锁操作,都会导致进程进入睡眠状态,从而让出 CPU
2. 睡眠补偿
如果一个进程一直在睡眠,那么它的 vruntime 是非常小的,当睡眠中的进程被唤醒时,基于 CFS 的调度逻辑,会一直持续运行当前进程,知道 vruntime 不是最小的时候,才会选择下一个进程来调度
理论上来说,其实睡眠中的进程,不应该计算 vruntime,因为这部分睡眠的时间,是这个进程放弃运行的时间
因此,内核为了解决 sleep 进程获得过长时间的问题,增加了一个阈值限制,当进程被唤醒时,取当前运行队列的最小vruntime,并 + 上一个偏移量,这个偏移量默认是 1/2 个调度周期,12ms
也就是说,当进程被唤醒之后,至少会得到 4ms 完整的运行时间,这个时间不可被中断,除非进程主动让出 CPU
staticvoidplace_entity(structcfs_rq *cfs_rq, structsched_entity *se, intinitial){u64 vruntime = cfs_rq->min_vruntime;/** The 'current' period is already promised to the current tasks,* however the extra weight of the new task will slow them down a* little, place the new task so that it fits in the slot that* stays open at the end.*/if(initial && sched_feat(START_DEBIT))vruntime += sched_vslice(cfs_rq, se);/* sleeps up to a single latency don't count. */if(!initial) {unsigned longthresh = sysctl_sched_latency;/** Halve their sleep time's effect, to allow* for a gentler effect of sleepers:*/if(sched_feat(GENTLE_FAIR_SLEEPERS))thresh >>= 1;vruntime -= thresh;}/* ensure we never gain time by being placed backwards. */se->vruntime = max_vruntime(se->vruntime, vruntime);}
极端情况下,我们可以模拟一个进程,不断的睡眠和被唤醒,就可以触发这个逻辑
3. 最短保证运行时间
CFS 还有一个机制,就是 sched_min_granularity_ns ,主要是为了保证时间片机制不会被无限分割下去的一个防御机制
确保每个可调度的进程,都有一个足够的 CPU 时间片
在 sched_min_granularity_ns 时间内,除非进程主动让出 CPU,否则其他所有进程都必须在队列里等待