这是google在13年发表的一片论文:https://dl.acm.org/doi/10.1145/2465351.2465388
这篇论文里,最有价值的地方在于建立了一个对业务透明,能够实时感知在线业务运行质量,并且能自动优化的机制
基本概念
- CPI:uses cycles-per-instruction,平均每条指令消耗的时钟周期(时间),相当于指令执行的代价。
现代处理器均有多级缓存,类似下面这样的一条指令:“ mov 0x200160(%rip),%rax ”,其执行时间由缓存是否命中决定(L0/L1/L2)。
CPI的争议
大家比较担心CPI是否能够准确的反应应用程序的行为,文中指出:
- 相关性如何(结论很好)
- 不同的任务执行的指令存在巨大的差异(不是个问题)
- CPI是结果,不是原因(没关系,足以反应问题)
- CPI不能反应网络和磁盘的干扰(CPU的干扰足够多)
对于CPU密集型task而言,CPI与应用程序的延时相关性为0.97,而对于瓶颈在网络io的应用程相关性仅为0.68~0.75(由于网络变慢,或者下游变慢)。
如何收集CPI
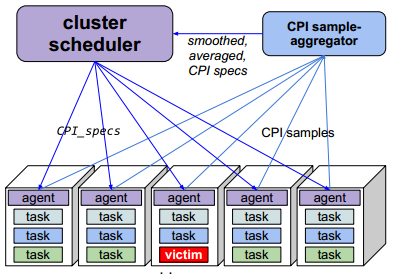
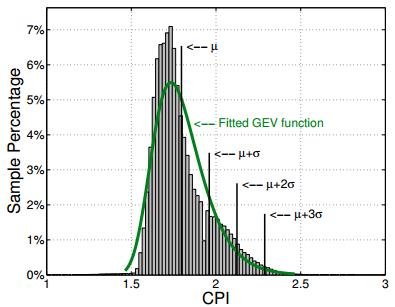
如图所示:
- 使用一个deamon进程,每分钟采集10s task的CPI(cgroup级别,注意这里使用counting模式,性能开销为每次上下文切换时需要多保存几个counter,开销<0.1%)
- agent将数据汇报给 CPI aggregator,聚合同一个服务同一CPU型号的CPI,并求得均值和均方差
- 注意这里聚合的维度是没有时间的,上右所示为webserver两天的CPI值统计
生成{job, cpu_model, mean, std},并最终传递到Agent上,用于预测task的CPI。
这里需要注意的就是一个在线服务全天的压力不同,CPI会有存在差异,但聚合没有考虑时间维度。一个可能的解释是服务必须全天满足服务质量,所以全天数据汇聚后的预测结果首先是可行的。只不过这个预测模型的灵敏度可能不高,可以按时间分桶,比如每小时一个桶,取每天相同位置的数据用于聚合。
如何使用CPI数据
干扰检测在agent完成,当task的CPI高于mean + 2*stddev时(5分钟内3次判定成功),则判定为task受到干扰。Google的服务分为product和non-product,对应我们的在线服务和离线作业。当product task受到干扰时,需要分析并抑制干扰源(单纯的限定non-product的总体cpu利用率并不能解决问题,需要对症下药)。
这里假设最近一段时间(10分钟)的cpi采样值为[c1, c2, …, cn],non-product task的cpu利用率为[u1, u2, …, un],通过计算这两者的相关性来判断嫌疑的task,变化规律越接近就认为其概率越高。作者通过将ui归一化使得∑ui = 1,并通过如下算法来计算相关性:

correlation(V,A)在[-1, 1]之间,每个task的计算需要消耗100us。根据作者的经验当其大于0.35时,判断就非常准确了。当分析得到一个嫌疑的task时,将其cpu限制到0.1core的方式来抑制其运行5分钟(不直接杀死是因为重新调度一个task有不可忽视的部署开销,这个决定交给上层调度框架)。
当然也存在一种情况是product task之间的相互干扰,因为product task不允许限制cpu,只能选择把自己迁移到其他机器上运行。

其他结论
- 在google的环境中,这种干扰发生的频率为0.37/machine day
- 对于product jobs来说,准确率70%。这个策略可以将product task的cpi中值降低0.63
- 干扰和机器利用率的无关,和job的平均CPI强相关
