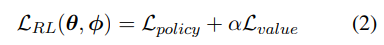最近 openai 发布圣诞系列的第一弹,就强调了强化微调,基于这个,可以让小模型结合行业数据,做到比大模型更强的推理效果
然后研究了下字节之前发过的类似的一篇论文:https://arxiv.org/pdf/2401.08967
1. 背景
1.1. 传统的 CoT 训练方法
虚线之上是传统的 CoT 训练方法,就是使用数据集(x, e, y)不断的训练基础模型,让基础模型获得推理能力
比如 gsm8k 数据集:https://huggingface.co/datasets/openai/gsm8k/viewer/main/train?p=1&row=167
这个数据集里面每一行就是一条训练数据,包括3部分:
x就是问题
e就是解决这个问题的思路
y是答案
但是这种训练方法,模型推理的泛华能力是比较弱的,因为它只能学习到一种解题思路,就是数据集中的思路
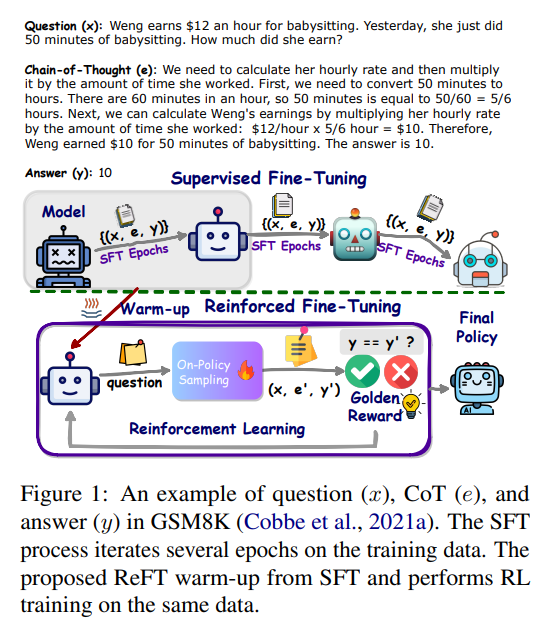
1.2. ReFT:Reinforced Fine-Tuning
训练思路和 SFT 很不一样同一条数据集,SFT 会反复训练多次,让模型在数据集上误差最小。这样训练出来的模型,对于解决数据集中的问题肯定是没问题的,但是对于解决数据集的其他问题,就不一定是最佳的了。这个时候回答问题的质量取决于数据集的质量和规模ReFT 只需要1~2次预热,得到一个基础的模型,然后通过强化学习,让模型主动去探索不同的解题路径,这样得到的模型,泛化能力是最强的
如上图,ReFT 有2个核心阶段:
- warm-up:xx
- 强化学习阶段:specifically Proximal Policy Optimization (PPO)
特别注意:ReFT 并不依赖额外的训练数据集通过这个方法,论文使 CodeLLAMA 和 Galactica 模型在GSM8K、MathQA、SVAMP数据集上,泛化能力得到了显著提高
2. 方法
核心算法和前面所述一样,2个阶段:
- warm-up
- 强化学习阶段

2.1. warm-up state
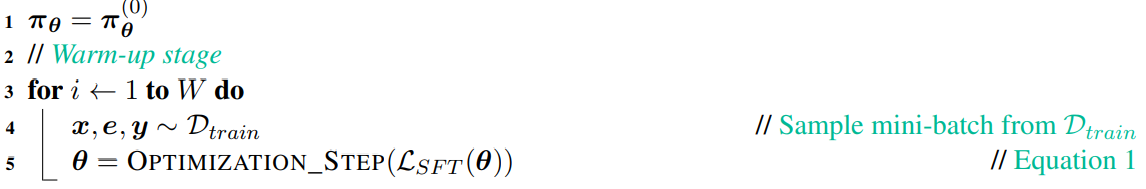
使用原始数据,训练 W 次,让模型获得 “初步” 的解题能力
warm-up 阶段定义的损失函数是:
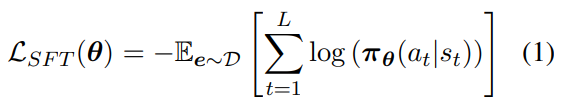
其中:
- θ是个超参,用来控制 πθ 策略的
- L是CoT长度,也就是e的长度
- a_t 表示 e 的第 t 个 token,e = [a1, a2, …, aL−1, aL],每次 decode 一个 token
- s_t 表示第 t 个时刻的环境状态,这是增强学习领域的基本术语,s_(t+1) 表示在 s_t 时刻选择 a_t 后的下一个状态,当 t = 0 时,也就是初始时刻,s_0 就是输入
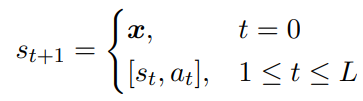
- πθ是一个环境策略,πθ(a_t|s_t) 表示在超参θ下,给定状态s_t下选择a_t的概率
疑问:
- 看起来这个策略函数πθ,非常关键,这个环境策略怎么设计的?
2.2. Reinforcement Learning
上述 warm-up 阶段只是让模型具备基础的推理能力,还远不够。强化学习需要通过环境反馈(奖励),让模型学习到最佳的策略 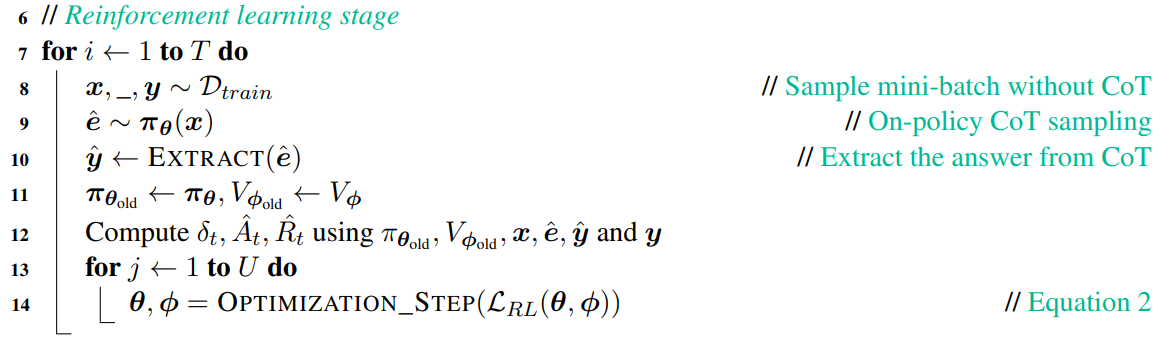
这一阶段,论文定义了一个新的损失函数 $L_{RL}(θ, \phi)$,这个损失函数,是根据 δ_t,A_t,R_t 计算出来的
2.2.1. 奖励模型
首先定义下基本的奖励模型,如下:

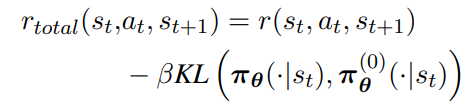
- 设计奖励(环境反馈)
- 正确的结果(如果算出y)要奖励
- 错误的结果(非y)不奖励
- 近似的结果(如果是个数字),部分奖励。不过论文后面也实验证明,即使去掉这部分,对效果影响也不大,所以这一步不是关键部分
- 计算 Kullback-Leibler 离散程度防止过于发散,这个值衡量的是模型当前的策略与初始策略之间的差异。这样做的目的是鼓励模型不要偏离初始策略太远,同时也能学到有效的策略
2.2.2. 优势估计 – A
a_t 表示我们在第 t 时刻选择生成的 token
但我们怎么知道选择 a_t 是不是一个最佳的决策?这个时候要引入一个叫优势估计的函数
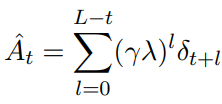
其中:
- λ ∈ (0, 1] is the discount factor for rewards, and
- γ ∈ [0, 1] is the discount factor for TD
- δ_t:这是一个时间差分因子,表示实际观测值和预测值之间的差距。这个非常重要
因此,A 计算的是 t 时刻之后未来所有时间差分 δ_t 的折现值,t 越大,参考价值就越小(这2个因子都是 < 1,因此 l 次方一定是越来越小)
A 越大,表示当前这个动作在未来就是平均最优的(不管后面你选啥 token),从而帮助模型做出更优的决策
再把 δ_t 展开理解一下:
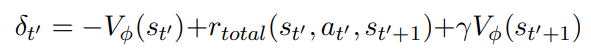
其中 VΦ 表示 s_t’ 状态下的预测价值因此,δ_t 计算的是 t 时刻实际观测到的奖励值 r_total,和预测的状态价值 VΦ 之间的差距
参考:
- 时间差分法(TD方法)
- OpenAI o1的真正前世竟来自字节?ReFT技术超越传统的数学微调能力,让GPT实现进化_字节跳动reft csdn-CSDN博客
2.2.3. 总回报 – R
基于上面的奖励模型和优势估计,我们很容易得到总回报的函数定义
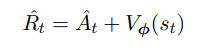
这里表示的是预期的总汇报?当前状态 s_t 下的预测的价值 VΦ 和选择 a_t 的所带来的未来的贴现值 A
疑问:
- VΦ 是当前状态下的预测价值,为啥不用实际观测到的价值?
2.2.3. 损失函数 – L
这里面分为策略损失和价值损失
todo(fangdong):先知道这么算吧,还不太理解为什么这么设计。论文也没细讲,可能有些增强学习的背景知识在这里面
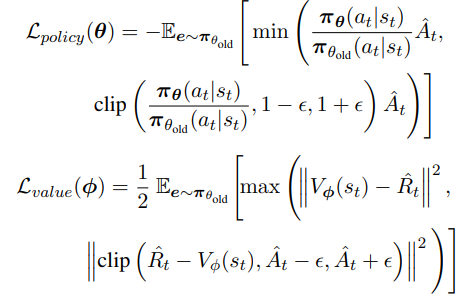
最后总的损失: