https://mp.weixin.qq.com/s/uK1owRF53FW4WI7nldYadg
https://arxiv.org/pdf/2311.15566.pdf
业界首个,在可抢占式实例上运行的分布式大语言模型(LLM)服务系统
目标:LLM 降本 -> 抢占式 GPU 实例 -> 怎么更好的用这些抢占实例
相比直接使用抢占式GPU实例,SpotServe 可以将推理引擎的长尾延迟降低 2.4x – 9.1x
LLM 特点:
- 高计算量
- 大内存占用
无论是哪一点,都意味着成本昂贵
把 LLM 运行在随时可抢占的 GPU 实例上
传统的方法,MArk、Cocktail,单实例多GPU卡,运行一个 small DNN 模型,通过请求重定向或者冗余计算来处理抢占,但是这种方式只是和数据并行这种小的DNN模型,不适合LLM
LLM 会同时使用数据并行、模型并行、流水线并行多种技术,单个实例抢占会影响整个多个实例的计算结果
所以需要有更有效的方法
亮点:第一个做推理容错的论文(其他的都是在做训练的容错)
SpotServe 的创新点:
- 动态配置并行度
- 实例迁移优化(复用模型参数、中间结果,减少迁移后的传输数据量):aws 抢占GPU实例,迁移后冷启动需要2m
- 高效利用宽限期(30s,尽量不中断推理)
1. 背景
1.1. Generative LLM Inference
当前类似的系统:
- FasterTransformer
- Orca
- FairSeq
- Megatron-LM
单次推理的总耗时,分析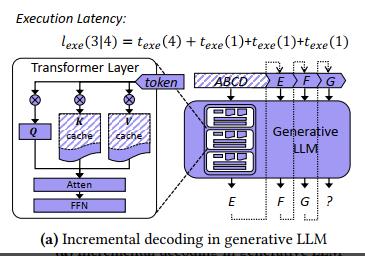
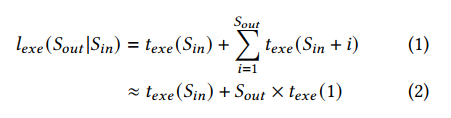
texe(Sin) 是输入序列的解码时间
Sout 是生成的 token 数量,texe(1) 是生成每个 token 的时间
KV cache 技术可以将每个 token 的生成时间优化到接近常量 (i.e., 𝑡𝑒𝑥𝑒 (1) in E.q.(2) and Figure 1a).
1.2. Distributed Inference of DNNs
典型的分布式DNN推理服务,比如,nvidia triton,主要是维护了多个并行的推理pipeline,每个pipeline其实就是一个类似 FasterTransformer 的推理引擎
推理服务接收到请求,然后dispatchs到这些推理引擎,每个推理引擎的所有GPU协作完成DNN推理,然后把结果返回给推理服务
单次分布式推理的耗时:𝑙𝑟𝑒𝑞 = 𝑙𝑠𝑐ℎ + 𝑙𝑒𝑥𝑒
前者是调度耗时:推理速度 > 输入速度、突发的请求
后者就是前面的推理耗时
Inter-operator parallelism:一般是层间、计算之间,基本就是流水线并行,将计算分成多个stag,会存在跨stag通信
Intra-operator Parallelism:计算内,一般就是张量并行,将一个计算分成多个 shard,设备之间通过集合通讯(All reduce)完成推理
不管是哪种并行,现在都是缺乏容错能力,单个GPU实例挂了,整个推理就hang住了。
1.3. Preemptible LLM Inference
现在已经有一些系统在做类似的工作:
- Varuna:dynamically changingthe hybrid data and pipeline parallel configuration after each instance preemption
- Bamboo:redundancy-basedpreemption recovery mechanism
但是这2个论文主要是针对训练的
它的问题是,比如一个 (P=2, M=2, batch size=1)的推理引擎,当 GPU1 被抢占时:
- 整个任务hang了,会产生调度开销(比如请求路由到别的推理引擎上处理)
- 疑问:为什么不提重新推理的开销?这个不是更大么
- 新GPU实例加入后,有很长的初始化过程(引擎启动、加载模型参数、重新推理,都很耗时)
- 抢占期间实例数减少,系统容易过载,导致请求堆积
推理的延迟大幅上升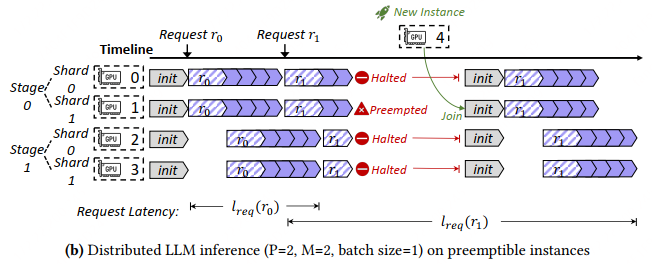
疑问:
- varuna 和 bamboo 没有解决这些问题吗?需要看下
2. SpotServe Design
和之前的其他论文,
不同点:一个是在做训练的checkpoint和restore,它这个是在做推理的checkpoint和restore
相同点:都是在框架层做
SpotServe 关注端到端的延迟,给出了一些解决方案,解决上面 LLM 分布式推理的几个关键问题
- 使用一些稳定的GPU实例,以快速的替换掉被抢占的GPU实例
- 减少重新初始化的时间,实现一种高效的上下文管理机制(KV cache 形式),用于保持推理进度,避免加载大量参数
- 动态并行技术,通过负载的自动感知,实现并行策略的动态调整和无缝切换
落地场景的思考:通过GPU超发提供资源,基于透明迁移 + 容器网络,可以让推理服务跑在廉价的抢占式算力上。
2.1. 整体架构
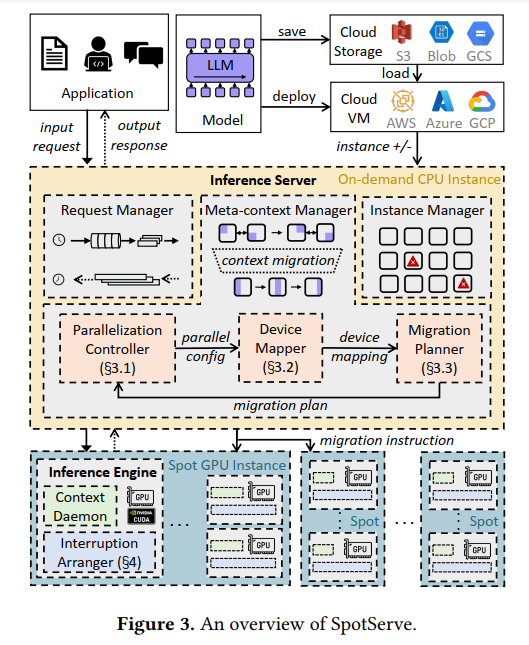
先对齐下概念
- 分布式的推理服务(server),也就是这里的 inference server(看代码应该是基于triton扩展的)
- 推理引擎,也就是这里的 inference engine(实际跑的是 fastertransformer)
engine 是一个单机的引擎,支持单机多卡,能够独立的执行推理任务,server 接收到请求,会均衡打散到各个inference engine上
一个GPU实例可能会部署多个engine(所以如果挂了一个GPU实例,会影响多个推理引擎)
Instance Manager 主要是和云厂商对接,感知实例抢占和获取新的实例
最核心的2个组件:
- Meta-context Manager【重点】:运行在稳定的CPU实例上
- 包括一个并行控制器、Device Mapper、Migration Planner
- Context Daemon:保存 model parameters 和 intermediate activations,运行在稳定的GPU实例 or 抢占式的GPU实例上,都行
- 疑问:If the inference engine has to be interrupted due to the preemption of dependent instance, the context daemon process is still alive and avoids to reload the context into GPU when restarting inference
还原系统架构(猜测):
- 当一个GPU实例(注意,一个GPU实例会影响多个engine)挂掉了
- 老架构怎么干的?只有 Rerouting:首先是把请求路由到不收影响的 engine 上重新推理,系统可能过载。新卡到之前,受影响的 engine 都不能工作,申请到新卡之后,受影响的 engine 完成迁移和重新初始化。
- 被中断的请求:耗时 = 被中断推理耗时 + 重新推理耗时 + 调度等待耗时(过载),不考虑过载的话,耗时不会超过2倍
- 其他请求:耗时 = 推理耗时 + 调度等待耗时(过载)
- SpotServe怎么干的?利用剩余的GPU卡,计算一个和原来最相似的一个拓扑,动态更改并行度配置(不需要重启实例),迁移数据。申请到新卡加入之后,也是一样的流程。相比老架构,可用的GPU实例多了很多
- 被中断的请求:耗时 = 推理耗时 + 更改并行度配置等待时间
- 其他请求:耗时 = 推理耗时 + 调度等待耗时(过载概率大幅降低,可能还有部分调度耗时)
- 动态更改并行度配置,是否会影响正在执行的请求?从日志推测,会,但是持续时间比较短,不会导致系统严重过载
- 老架构怎么干的?只有 Rerouting:首先是把请求路由到不收影响的 engine 上重新推理,系统可能过载。新卡到之前,受影响的 engine 都不能工作,申请到新卡之后,受影响的 engine 完成迁移和重新初始化。
2.2. Parallelization Controller
为了保证GPU实例被抢占后的性能,平衡latency、吞吐、成本,SpotServe 借鉴了其他系统[50]的思想,会动态的调整推理服务的并行度配置
并行配置用 𝐶 = (𝐷, 𝑃, 𝑀, 𝐵) 来表示
D 数据并行度
P 管道并行度
M 张量并行度(不是 Model 的 M)
B mini-batch size(实际上不会调整B)
核心算法
Adaptive configuration optimizer
简单来说:
- 如果 𝛼𝑡 比较小,那就选一个 latency 最好的配置
- 如果 𝛼𝑡 比较大,那就选一个 吞吐 最好的配置
注意:
- 𝛼𝑡 大还是小,取决于是否存在一个 C 能满足当前的 𝛼𝑡
- C 和 N、latency、吞吐的关系,需要提前测试
论文中的一些关键信息:
- Another baseline is modelreparallelization, which changes the parallel configurationlike ours, but has to restart and reinitialize all instance without context migration。更改并行度配置不需要重启实例?
- Another observation is that mixing on-demandinstances helps alleviate the overload due to the faithfulinstances acquisitions. 从图6可以看出,使用稳定实例,可以降低
2.3. Device Mapper
参考:
- 了解 KV cache:https://zhuanlan.zhihu.com/p/630832593
推理实例的并行度配置变更了之后,最简单粗暴的办法就是把所有GPU实例重启一遍,然后重新初始化,重头开始推理
这无疑是非常低效的
SpotServe 提出了一个非常轻量的方法,想办法复用现有的 model parameters 和 KV cache
核心思想:
SpotServe 把每一个GPU卡对应在分布式拓扑中的位置记录下来,就是整个 P-M-D,比如这个 GPU 是属于哪个 pipeline,哪个stag,哪个 shard
然后通过二分图最大匹配算法,然GPU实例尽可能的少动或者少传输量(类似差分传输?)
这块原理还需要细看下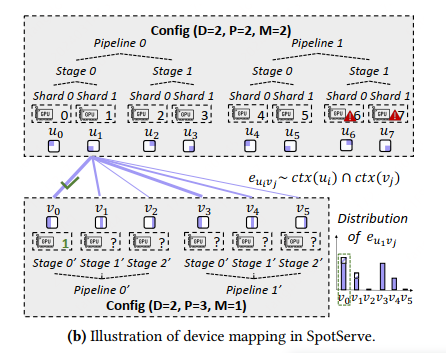
疑问:
- 如果掉了一个GPU卡,直接调整现有的并行度配置,可以接着推理?好像是可以的。
2.4. Migration Planner
一旦确定好新的拓扑结构,剩下的就是model parameters和KV cache怎么迁移的事情了,这个由 Migration Planner来负责执行
2个关键问题:
- xxx
- 内存占用问题,sender内存占用会降低,但是receiver内存占用会变高,如果迁移计划不合理,会导致peek内存占用非常高
解决方案
- 耗时问题:迁移的时候发送所有的上下文不合适(尤其是超大模型),提出一种渐进式的迁移方案,不同stag的实例可以并行干活,比如在stag1 GPU推理的时候stag2的GPU可以执行迁移
- 内存问题:优先迁移不会导致 Umax 耗尽的 layers,然后将最后剩下的可能会导致超过Umax的layers,转化为一个argmin max问题

这块有很多疑问:
3. Stateful Inference Recovery
推理本身是一个有状态的服务,怎么恢复?
由于不断的有实例被抢占或者新加入,SpotServe得决定什么时候处理上下文迁移
对抢占: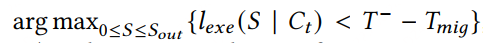
抢占我理解了,充分利用率抢占的宽限期,执行更多的推理
对新加入: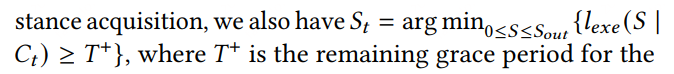
这个我没理解?
求一个让lexe(S|Ct) >= T+ 最小的 S 值,这个不就是等价于,当新加入的实例初始化完成后,立即执行上下文迁移么?
4. 实验评估
值不值得干,有没有场景
During the optimization, themaximum batch size 𝐵 is selected from {1,2,4,8}, 𝑆𝑖𝑛 is 512 and 𝑆𝑜𝑢𝑡 is 128
实验场景:
- 硬件:AWS g4dn.12xlarge instances (4 NVIDIA Tesla T4 GPUs per instance) -> A100 会有10-20倍性能提升?
- 刻意模拟过载,平均每分钟挂1个实例(引擎初始化、启动2分钟),并模拟了系统过载(比如20B的模型,请求速度 0.35/s,系统容量 = 6实例/12s = 0.5,挂掉1-2个实例就会出现过载)
- 不过载的情况下,20B 模型,单次推理耗时 13s,30B 模型,单次推理耗时 18s(这个受限于T4性能)
- 选取了12小时数据里面SpotServe表现最好的20分钟的数据
分三组实验:
- Reparallelization(重启+重新初始化):调整并行度配置,请求会被中断并重新推理
- Rerouting:重新路由,请求会被中断并重新推理
- SpotServe
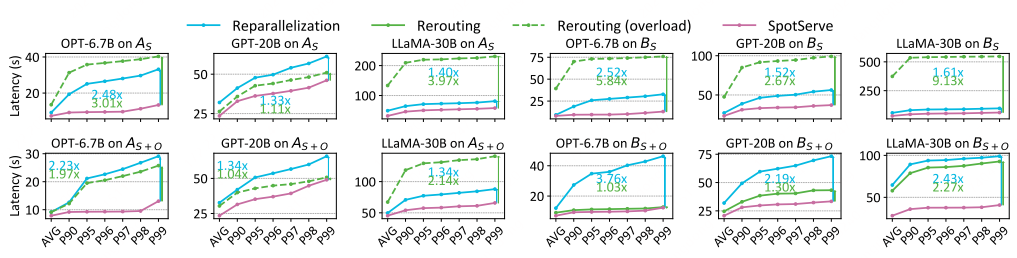
对照组A vs B:
A:12小时的数据 -> 天级别?
B:12小时内取20分钟的数据,应该是选取了长尾效果更显著的数据 -> 小时级别?
对照组:As+o vs As
As+o:同时使用 S 实例 + O 实例,S是抢占实例,O是稳定实例
As:只使用 S 实例
对照组:模型大小:
- 6.7B:
- 20B
- 30B
1)看数据
一些事实:
- xxx
- xx
一些疑问:
- 为什么平均延迟这么大?(实际上是用了T4卡,所以整体都很差,常规推理100ms搞定)
- 为什么p90和p99差异这么小?看着是模拟了过载,基本大部分请求都有调度耗时
- Reparallelization 不管是在6.7B,还是20B、30B数据上,使用了稳定实例之后,为什么延迟还大幅上涨了?这个非常奇怪(Rerouting和SpotServe都变好了)
原始的log数据
每个引擎的computation时间几乎是一样的,延迟并不在计算本身上
[2023-05-01 06:01:52.762243] interrupt query 246 at step 637 [schedule 10787.000, computation 14511.000, overhead 9.412]
[2023-05-01 06:01:52.762270] interrupt query 247 at step 637 [schedule 7724.000, computation 14511.000, overhead 10.015]
[2023-05-01 06:01:52.762301] interrupt query 248 at step 637 [schedule 4719.000, computation 14511.000, overhead 9.689]
[2023-05-01 06:01:52.762314] interrupt query 249 at step 637 [schedule 1797.000, computation 14511.000, overhead 9.974]
[2023-05-01 06:01:52.762321] response replica rank 0 close connection
[2023-05-01 06:01:54.670659] get response from replica id 0 (address: (‘172.31.7.8’, 45894))
[2023-05-01 06:01:54.670712] get response from replica id 1 (address: (‘172.31.4.130’, 46634))
[2023-05-01 06:02:04.530501] Request 246 arrival 708.319 latency: 37075.662, [schedule 14571.000, computation 20571.000, overhead 1933.662] seq_len: 512, replica id: 0
[2023-05-01 06:02:04.530595] Request 247 arrival 711.381 latency: 34013.337, [schedule 11508.000, computation 20571.000, overhead 1934.337] seq_len: 512, replica id: 0
[2023-05-01 06:02:04.530616] Request 248 arrival 714.387 latency: 31008.003, [schedule 8503.000, computation 20571.000, overhead 1934.003] seq_len: 512, replica id: 0
[2023-05-01 06:02:04.530631] Request 249 arrival 717.308 latency: 28086.291, [schedule 5581.000, computation 20571.000, overhead 1934.291] seq_len: 512, replica id: 0
[2023-05-01 06:02:08.095976] Request 251 arrival 723.131 latency: 25828.753, [schedule 3513.000, computation 18009.000, overhead 4306.753] seq_len: 512, replica id: 1
[2023-05-01 06:02:17.774642] Request 250 arrival 720.291 latency: 38347.381, [schedule 9845.000, computation 13245.000, overhead 15257.381] seq_len: 512, replica id: 0
[2023-05-01 06:02:17.774719] Request 252 arrival 725.915 latency: 32723.741, [schedule 9845.000, computation 13245.000, overhead 9633.741] seq_len: 512, replica id: 0
[2023-05-01 06:02:17.774739] Request 253 arrival 728.771 latency: 29867.602, [schedule 9845.000, computation 13245.000, overhead 6777.602] seq_len: 512, replica id: 0
[2023-05-01 06:02:17.774754] Request 254 arrival 731.588 latency: 27050.591, [schedule 9845.000, computation 13245.000, overhead 3960.591] seq_len: 512, replica id: 0
[2023-05-01 06:02:21.287038] Request 255 arrival 734.497 latency: 27654.200, [schedule 13421.000, computation 13182.000, overhead 1051.200] seq_len: 512, replica id: 1
[2023-05-01 06:02:21.287138] Request 256 arrival 737.340 latency: 24811.335, [schedule 11616.000, computation 13182.000, overhead 13.335] seq_len: 512, replica id: 1
[2023-05-01 06:02:21.287169] Request 257 arrival 740.336 latency: 21815.604, [schedule 8621.000, computation 13182.000, overhead 12.604] seq_len: 512, replica id: 1
[2023-05-01 06:02:21.287186] Request 258 arrival 743.158 latency: 18992.797, [schedule 5798.000, computation 13182.000, overhead 12.797] seq_len: 512, replica id: 1
[2023-05-01 06:02:31.019606] Request 259 arrival 745.986 latency: 25897.194, [schedule 12639.000, computation 13252.000, overhead 6.194] seq_len: 512, replica id: 0
[2023-05-01 06:02:31.019670] Request 260 arrival 748.766 latency: 23117.433, [schedule 9859.000, computation 13252.000, overhead 6.433] seq_len: 512, replica id: 0
[2023-05-01 06:02:31.019691] Request 261 arrival 751.848 latency: 20035.862, [schedule 6777.000, computation 13252.000, overhead 6.862] seq_len: 512, replica id: 0
[2023-05-01 06:02:31.019707] Request 262 arrival 754.798 latency: 17085.531, [schedule 3827.000, computation 13252.000, overhead 6.531] seq_len: 512, replica id: 0
2)看日志
一些事实:
- 只看 0506 这个时间的数据
- 日志和论文的对应关系
- ondemand 应该就是对应的 Ao+s(用spot实例和稳定实例),real 对应的就是 As(只用spot实例)
- baseline 对应的就是 Reparallelization,baseline-triton 对应的就是 Rerouting,naive 对应的就是 SpotServe
- 从日志来看,SpotServe 只是优化了overhead这部分,schedule和computation并没有优化
一些疑问:
- 日志中的 overhead 到底是什么,看代码是 tcp_overhead,tcp的传输耗时?
- 关于 schedule 部分耗时
- 为什么最前面的几个请求,仍然有10s的调度耗时??那会系统应该是完全空闲的,调度耗时来自哪里??
- SpotServe上了之后,长尾还那么大?
- 看日志主要是schedule,是因为常态过载吗?,所以如果系统不过载,是不是长尾影响很小了(即使长尾优化的小了,SpotServe还是有价值的,解决了很关键的一个问题)
- 如果不是调度过载,这个schedule具体是什么
- 动态 Reparallelization 会不会影响正在running的请求?
- 会。从日志看,GPU实例中断之后,除了被中断的请求(246-249),其他正在running的请求(250-255),overhead变大了,其他不受影响的请求 overhead 也变大了。但是持续时间很短
- 对于20B的模型,为什么速率是0.25的时候,schedule很小,overhead 很大,但是速率是0.35的时候,schedule很大,overhead很小?
- ondemand/naive_tpt0.25_cv6-0506/inference_service.log
- ondemand/naive_tpt0.35_cv6-0506/inference_service.log
5. 落地的一些思考
当前论文的数据,应用SpotServe之后,推理耗时仍然在10s-40s左右。但是SpotServe是过度关注了系统过载时SpotServe的优异表现,实际落地过程中是有很大的可操作空间的
总耗时 = 调度耗时 + 调整并行度配置耗时 + 推理本身的计算耗时
对于1个20B的模型:
总耗时 30s = 调度12s + 调整并行度配置5s + 推理13s
怎么落地?
- 推理13s:如果用a800之类的卡,应该能优化到 < 1s
- 调度12s:只要保证系统有足够的容量,不过载,这部分时间理论上就是0(有论文原始数据可以佐证)
- 调整并行度5s:只有当GPU实例挂了的那一刻,需要变更并行度配置,才会有这个耗时。
- 论文里面是1分钟挂一个实例,实际场景中如果能控制到小时级别的挂,那对p99基本没有影响
- double query 机制:超时了自动重新rerouting
| 场景 | 备注 | SpotServe | rerouting(透明迁移) | |
| 单实例单卡 | 一个推理引擎用一张卡 | 退化成rerouting了 | 首选 | |
| 单实例多卡(张量并行、数据并行) | 一个推理引擎用多张卡 假设:可以做到小时级别挂一个实例,而不是分钟级别 |
冗余足够 (挂1个GPU,用 double query) |
p99 不变(5s/3600s=99.8%) p99.9 总耗时增加5s(推理耗时 + 变更并行度配置5s) |
首选 p99 不变 p99.9 总耗时最多2倍,100ms ~ 5s(重新推理 + 0调度等待) |
| 冗余不够 (挂多个GPU) |
首选 p99 总耗时可能增加5s-10s(推理耗时 + 变更并行度配置5s) |
p99 总耗时可能增加几分钟,取决于新GPU实例的加入时间 | ||
结论:
SpotServe 关注了系统在极端情况下(实例分钟级别的挂、系统严重过载)的长尾表现
SpotServe 实际故障恢复预计需要2s-5s时间(20B~30B,模型越大时间越长)
考虑系统常态下不过载的情况下,小时级别挂一个GPU实例左右的话,SpotServe 的推理长尾p99分位应该不受影响,p99.9分位增加5s
所以 SpotServe 适合推理延迟成倍大于5s的服务,当推理延迟 < 2s 时,考虑性能的话首选 rerouting 方案,考虑成本的话首选SpotServe方案(大概估计能节省10%~20%成本,因为rerouting方案会浪费掉20%的卡)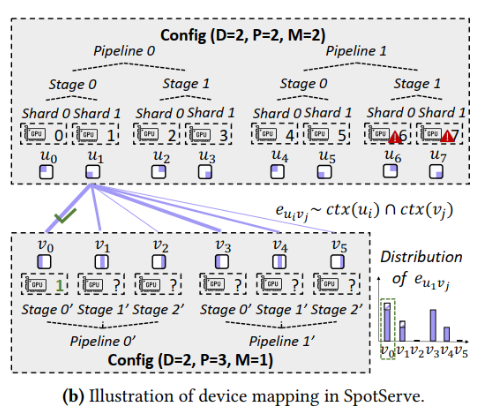
一些创新点:
- 变更并行度配置,为什么需要5s(系统初始化?传输?)?能不能在框架这一层优化调?如果能解决这个问题,那整个SpotServe架构的场景就更普适了,不用考虑冗余的问题了