使用 nsys & ncu 来分析 vllm 性能
大模型这么火,但却发现网上很少有相关的性能分析的资料,绝大部分都是偏理论的性能分析
最近发现了 nvidia 有很好的性能分析工具,nsys 和 ncu,于是决定用来研究下 vllm 的 decode 性能,本文将是一些记录,方便大家更好的学习和使用
1. nsys & ncu 基础
1.1. 简介
在之前的CUDA版本中,所附带的性能分析工具主要是nvvp(NVIDIA Visual Profiler)和nvprof,前者是带有图形界面的分析工具,后者是命令行工具。在CUDA官方文档中有这样一段描述:
Note that Visual Profiler and nvprof will be deprecated in a future CUDA release.The NVIDIA Volta platform is the last architecture on which these tools are fully supported. It is recommended to use next-generation toolsNVIDIA Nsight Systemsfor GPU and CPU sampling and tracing andNVIDIA Nsight Computefor GPU kernel profiling.
所以nvvp与nvprof现在已经废弃了,现在nvidia主要的性能分析工具就是nsys(Nsight System)和ncu(Nsight Compute)。
nsys是系统层面的分析工具,nsys 主要用来分析函数热点,产生类似于火焰图之类的数据。
ncu则是用于分析一个具体的核函数,更多的是看核函数执行过程中 GPU 硬件的性能,比如内存带宽和 SM 利用率等等。
两者均有图形界面版本和命令行版本。这2个工具一般都是组合起来一起使用的
1.2. 安装
需要用邮箱注册一下,然后下载:
- ncu:https://developer.nvidia.com/tools-overview/nsight-compute/get-started
- nsys:https://developer.nvidia.com/nsight-systems/get-started
需要下载 deb 包和 msi 安装包前者安装在容器镜像里面,用于采集 Profile 数据后者安装在 windows 笔记本上(如果你是 mac,就装 mac 版就行),用于分析 Profile 数据比如我在容器里安装的就是:
NsightSystems-linux-cli-public-2024.6.1.90-3490548.deb
nsight-compute-linux-2024.3.2.3-34861637.run
1.3. 基本用法
nsys:
nsys profile -o /tmp/profile.out -f true python3 vllm_offline.py
运行结束会产生一个 profile.out.nsys-rep 文件
用 windows 打开就得到
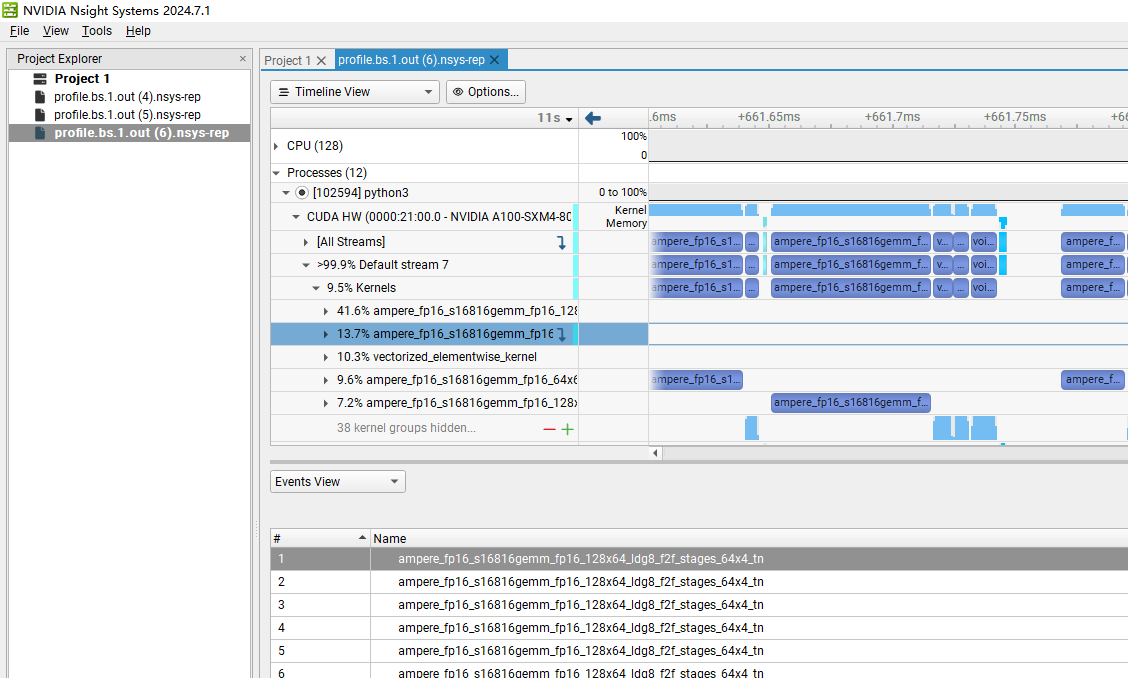

ncu:
ncu -o /tmp/profile.out -k ampere_fp16_s16816gemm_fp16_128x256_ldg8_f2f_stages_64x3_tn –set full –target-processes all python3 vllm_offline.py
运行结束会产生一个 profile.out.ncu-rep 文件用 windows 打开就得到: 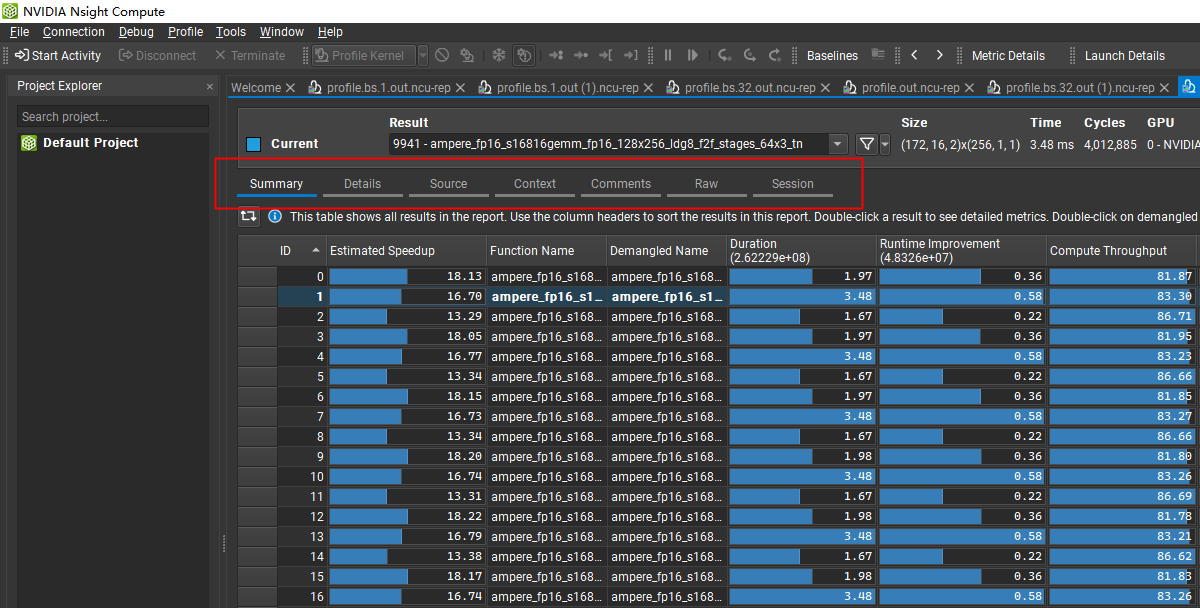
好了,后面开始正式进入分析主题
2. nsys(Nsight Systems)
nsys 提供多种视角的数据,帮助我们分析整个推理的性能
官方帮助文档:https://docs.nvidia.com/nsight-systems/UserGuide/index.html#reading-your-report-in-gui
2.1. nvtx
由于 nsys 和 ncpu 默认上都是整个进程粒度 profile 性能数据的。进程结束后会产生一大堆的性能数据,全部 profile 的话耗时很长,而且基本没有可读性(因为底层的 kernel 函数很难看出区别)
如果你只想关心其中一段代码的性能数据,或者几个特定 kernel 的性能数据,怎么办?
nvtx 提供了一个非常简单有效的办法,可以让业务指定一段 Profile 的范围,并指定一个别名
官方文档:https://nvtx.readthedocs.io/en/latest/annotate.html
最常见的用法就是 start_range() end_range()
比如我只想分析 vllm 的 decode 阶段的性能,可以这样
lib/vllm/model_executor/models/llama.py
class LlamaModel(nn.Module):
def forward(
self,
...
) -> torch.Tensor:
self.nr_step += 1
for i in range(len(self.layers)):
layer = self.layers[i]
rng = nvtx.start_range(message="my_decode_%d_%d" % (self.nr_step, i), color="blue") // 这里
hidden_states, residual = layer(
positions,
hidden_states,
kv_caches[i],
attn_metadata,
residual,
)
nvtx.end_range(rng)
Profile 的时候,我们就可以通过指定 my_decode_10_5 来分析 decode 第10个token的第5个Layer时的kernel性能
ncu –nvtx –nvtx-include my_decode_10_5 -fo /tmp/profile.bs.1.out –set full –target-processes all python3 vllm_offline.py
ncu --nvtx --nvtx-include my_decode_10_5 -fo /tmp/profile.bs.1.out --set full --target-processes all python3 vllm_offline.py ==WARNING== Backing up device memory in system memory. Kernel replay might be slow. Consider using "--replay-mode application" to avoid memory save-and-restore. ....50%....100% - 49 passes ==PROF== Profiling "ampere_fp16_s16816gemm_fp16_1..." - 1: 0%....50%....100% - 49 passes ==PROF== Profiling "rotary_embedding_kernel" - 2: 0%....50%....100% - 47 passes ==PROF== Profiling "reshape_and_cache_flash_kernel" - 3: 0%....50%....100% - 47 passes ==PROF== Profiling "flash_fwd_splitkv_kernel" - 4: 0%....50%....100% - 49 passes ==PROF== Profiling "ampere_fp16_s16816gemm_fp16_6..." - 5: 0%....50%....100% - 47 passes ==PROF== Profiling "fused_add_rms_norm_kernel" - 6: 0%....50%....100% - 49 passes ==PROF== Profiling "ampere_fp16_s16816gemm_fp16_1..." - 7: 0%....50%....100% - 47 passes ==PROF== Profiling "splitKreduce_kernel" - 8: 0%....50%....100% - 49 passes ==PROF== Profiling "act_and_mul_kernel" - 9: 0%....50%....100% - 48 passes ==PROF== Profiling "ampere_fp16_s16816gemm_fp16_6..." - 10: 0%....50%....100% - 49 passes Processed prompts: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [09:06<00:00, 546.68s/it, Generation Speed: 0.04 toks/s] Prompt: 'Hello, This blog post delves into the art and science of prompt engineering, offering insights and strategies to harness the full capabilities of LLMs,', Generated text: ' including the upcoming GPT-4. We will explore how to construct prompts that elic' ==PROF== Disconnected from process 22049 ==PROF== Report: /tmp/profile.bs.1.out.ncu-rep
2.1. 火焰图(Timeline View)
程序分为 GPU 时间和 CPU时间
- GPU 时间:核函数的执行时间。
- 通常我们所说的算子实现都是在 .cu 文件里的,但是一个 cu 会编译出多个核函数。nvcc 在编译 cu 文件的时候,只有 __global__ 标识的函数才会编译为真正的 kernel 函数,非 __global__ 标识的函数只会编译为 cpu 指令
- CPU 时间:py 代码,go代码,cu中的非 global 代码
如下图:
- CUDA HW 对应 GPU 核函数耗时
- Threads 对应 CPU 耗时
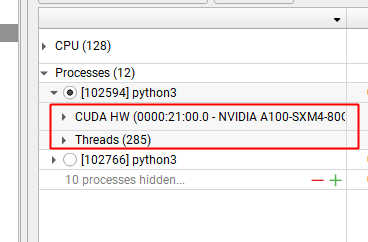
Timeline View 分2个窗口:
- 左边:函数的热点分布,看程序时间大头消耗在什么地方
- 右边:看函数的执行流,支持缩放
2.1.1. GPU 耗时
CUDA HW 耗时可以按照 Stream 划分
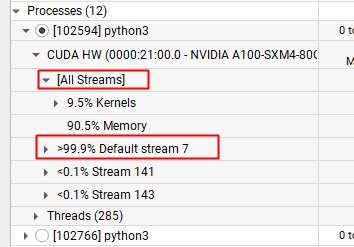
- All Streams:不区分所有的 Stream,全部核函数整体分析
- Stream N:只看当前这个 Stream 的核函数耗时
一般来说,如果写代码的时候没有特别指明,都会在 Default stream 里面,所以不用特别关注这个。我们一般看 All Streams 即可 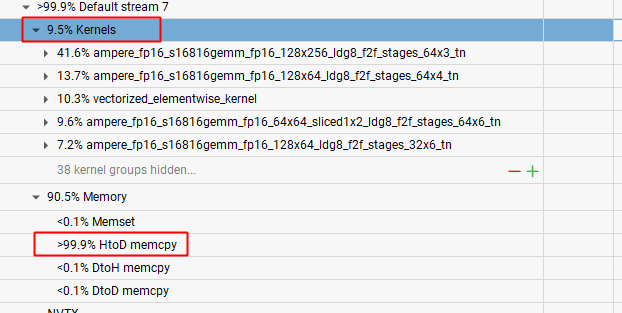
注释:
- 9.5% 的时间在执行 Kernels,prefill 和 decode 阶段的耗时都在这里面
- 90.5% 的时间在执行显存拷贝,而且基本全部都在 HtoD,这个地方就是 vllm 启动的时候,把模型权重从内存加载到 GPU 的时间
2.1.1.1. 整体耗时
我们再看下右边的函数执行流整体上看,分3个阶段:
- 初始化:最左边,主要就是模型加载,权重拷贝
- 中间有一段不知道干啥的,没细看,先忽略
- Prefill & Decode:开始进入推理阶段,Prefill和Decode都在这里面
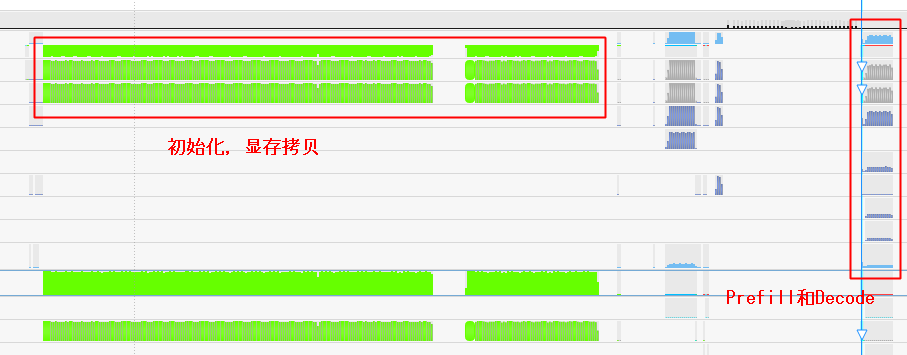
2.1.1.2. Decode 耗时
这个图是可以放大的,我们把 Decode 阶段放大,就能明显看到,有20个山峰,其实代表了20个token的计算
- 最左边有1个初始的token,这个执行的就是 Prefill
- 接着右边继续生成了19个token,因为我设置了 max_tokens = 20,所以输出到20个字符的时候,生成就结束了

2.1.1.3. 单个 Token 耗时
我们继续把这个图放大,分析单个 token 的执行流,有32个山峰,代表了模型有 32 个 layer,因为 transformer 架构就是 layer by layer 的,层和层之间串行执行
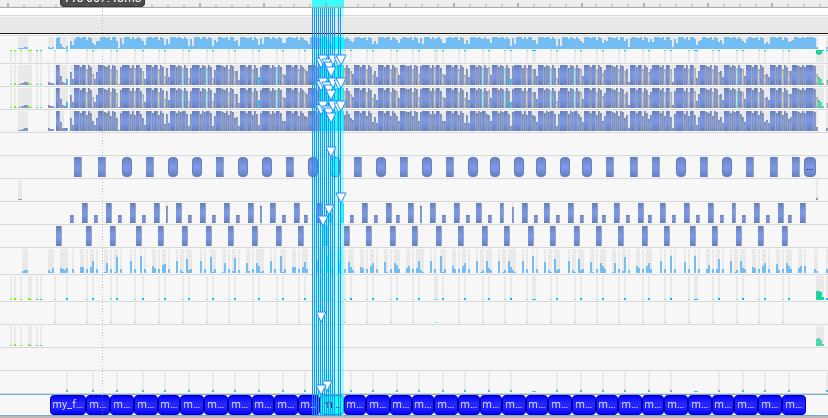
2.1.1.3. 单个 Layer 耗时
当我们看单个 layer 的耗时,我们就得看下 transformer 的原本架构了,我们知道 transformer 本身就是 N * layer 的一个模型,每个 layer 都是同构的,上层 layer 的输出是下层 layer 的输入如下,一个 layer 包含7个算子
- LayerNorm
- Fused QKV Gemm
- fused_masked_multihead_attention
- Out Linear
- LayerNorm
- FFN1
- FFN2
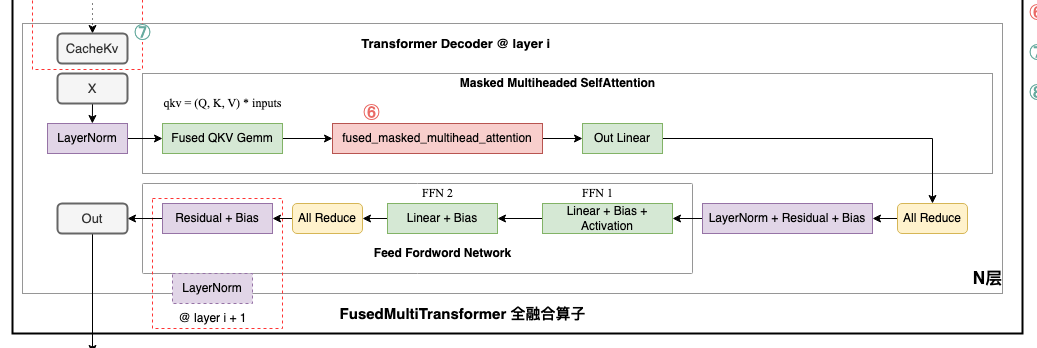 我们继续把之前这个火焰图放大,分析 token 生成中,每个 Layer 的耗时,我们可以显式的看到,这个阶段主要就是 4 个矩阵的计算
我们继续把之前这个火焰图放大,分析 token 生成中,每个 Layer 的耗时,我们可以显式的看到,这个阶段主要就是 4 个矩阵的计算
- ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_stages_32x6_tn:对应 Fused QKV Gemm
- ampere_fp16_s16816gemm_fp16_64x64_sliced1x2_ldg8_f2f_stages_64x6_tn:对应 Out Linear
- ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_stages_64x4_tn:对应 FFN1
- ampere_fp16_s16816gemm_fp16_64x64_sliced1x2_ldg8_f2f_stages_64x6_tn:对应 FFN2
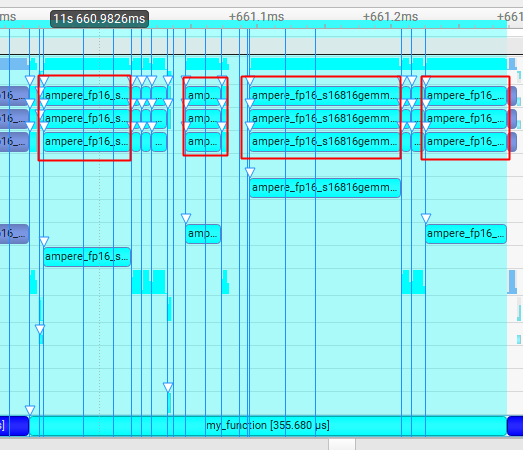
为什么没看到我们之前说的 attention 计算呢?别着急,后面 Events 视图会继续讲解
2.1.2. CPU 耗时
xx不是那么重要
2.2. 执行流(Events View)
nsys 提供一种能够看到核函数执行流的视图,就是 Events View。对于在 GPU 上执行过的所有核函数,都会被完整的记录下来,以便后续分析用法就是,右键你想分析的函数区域,选择 Apply Filter
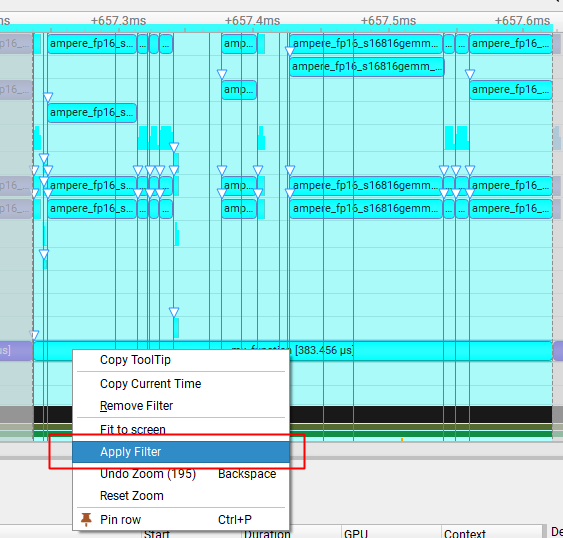
这样我们就得到了 Decode 阶段单个 Layer 的全部执行逻辑我们前面说单个 Layer 一共有7个算子,之前缺少的 LayerNorm 和 Attention 计算就在这里了 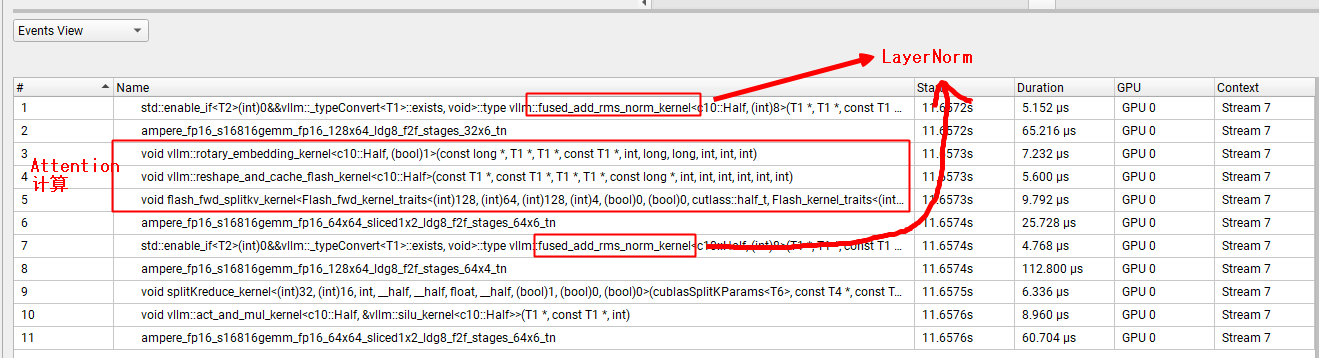 显然,在这里面:
显然,在这里面:
- Attention 计算的耗时不是大头。(特别注意,这里的 Attention计算是狭义的 Attention 计算,特指 softmax 和 AV 的计算)
2.3. 统计视图(Stats System View)
这个视图能帮助我们从另外一个视角分析 GPU 的核函数执行行为常用的就3个:
- Kernel Summary
- Kernel/Grid/Block Summary
- Kernels/MemOps
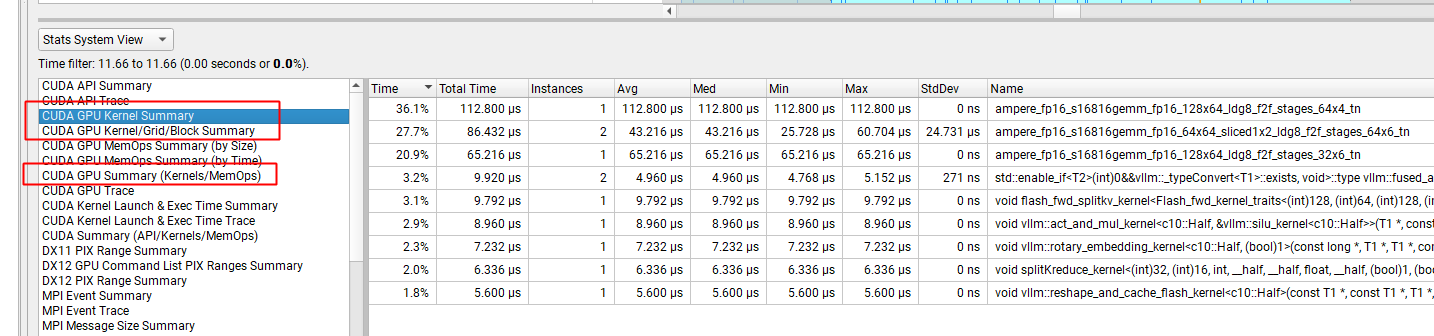
这里就不展开讲了,有兴趣的自己翻一翻右侧的 Instances 表示核函数的执行次数
3. ncu(Nsight Compute)
一旦我们通过 nsys 知道了 vllm 的整个推理耗时,下一步就是需要针对热点核函数,分析耗时过长的原因
这个时候 ncu 就非常有用了,ncu 能够帮助我们分析到一个核函数在 GPU 上执行的全部细节,甚至包括整个硬件拓扑的内存数据传输的性能
官方帮助文档:https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html
运行命令,分析 decode 第10个token的第5个Layer的所有核函数,如果要指定单个核函数,用 -k $kernel_name 就行
ncu –nvtx –nvtx-include my_decode_10_5 -fo /tmp/profile.bs.1.out –set full –target-processes all python3 vllm_offline.py
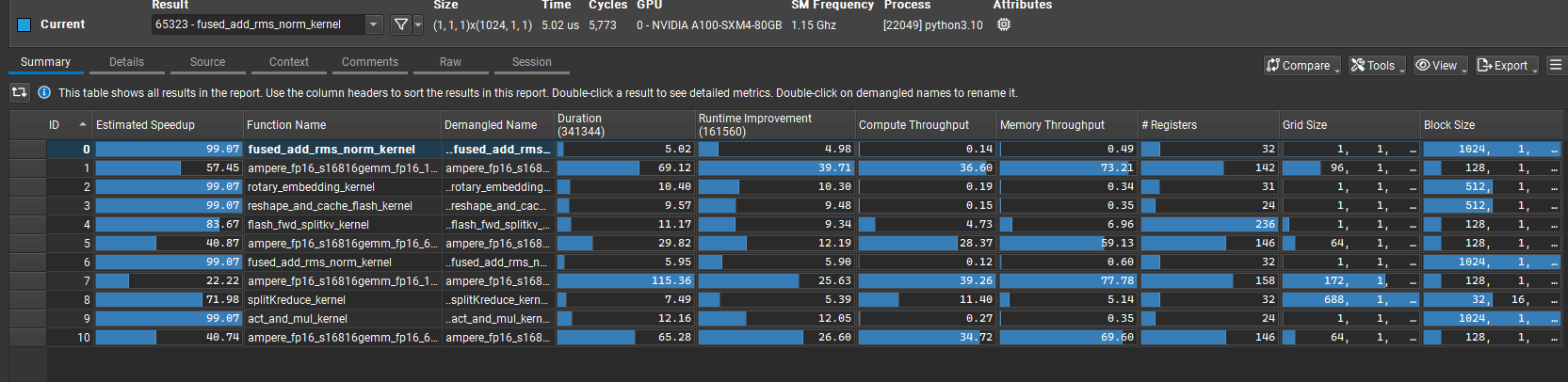
打开 ncu-rep 文件,首先映入眼帘的是这个图表示当前捕捉到的核函数的汇总情况(由于我指定了只捕捉单个核函数,这个核函数会被执行多次)几个关键字:
- Duration:单位是毫秒,表示执行时间
- Compute Throughput:计算吞吐,表示 SM 利用率
- Memory Throughput:内存吞吐,特指HBM带宽利用率(不包括L2,L2的带宽利用率在 Memory Workload 里可以看到)
- Grid Size 和 Block Size,这是 cuda 编程的基本概念,可以自行百度一下
 接下来,我们点开 Detail,展开深入分析每一项的性能数据(这里只看4个比较重要的)
接下来,我们点开 Detail,展开深入分析每一项的性能数据(这里只看4个比较重要的)
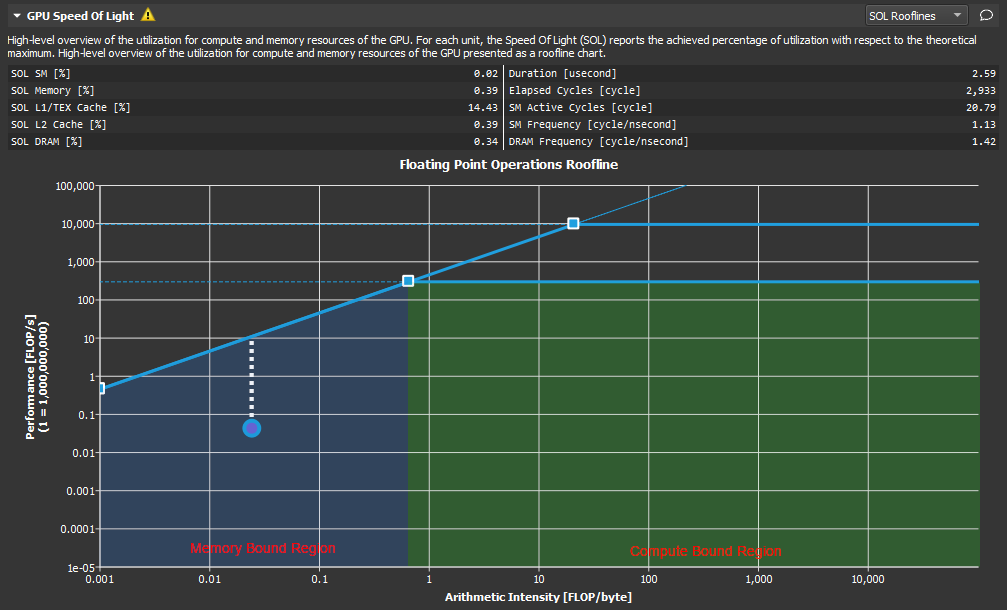
3.1. GPU Speed Of Light Throughput
更多请参考:https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html#roofline-charts右上角选 All
比较重要的几个吞吐指标: 
- Compute (SM) Throughput [%] 83.17:表示执行当前 kernel 时的 SM 利用率
- Memory Throughput [%] 47.02:表示执行当前 kernel 时的访存带宽利用率。这里访存带宽利用率低是因为计算大,访存等计算导致的
- SM Frequency [Ghz] 1.15:SM的运行频率
- 之前有一篇文章 LLM Decode GQA & GEMV算子性能分析(一),讲 A100 上算子运行时间不符合预期,是因为 A100 的SM频率是1.15,而L20的频率是2.33,所以L20可能更适合推理
- DRAM Frequency [Ghz] 1.59:访存的运行频率
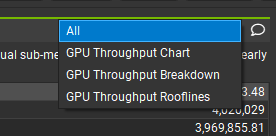
另外还有一个比较重要的其实是 Rooflines 分析,这个主要是用来分析算术强度算术强度有3个概念:
- 硬件理论的算术强度
- 比如 A100:浮点运算能力是312T,显存带宽是2T,那么算术强度就是 312T/2T,也就是156
- 算子理论的算术强度:这个点叫 Ridge Point,这个理论是根据实际运行过程中的 peak 吞吐计算出来的,说明实际运行峰值可以做到这么高
- 比如当前这个矩阵运算,fp16 的理论运算强度是 3.91
- 算子实际运行的算术强度
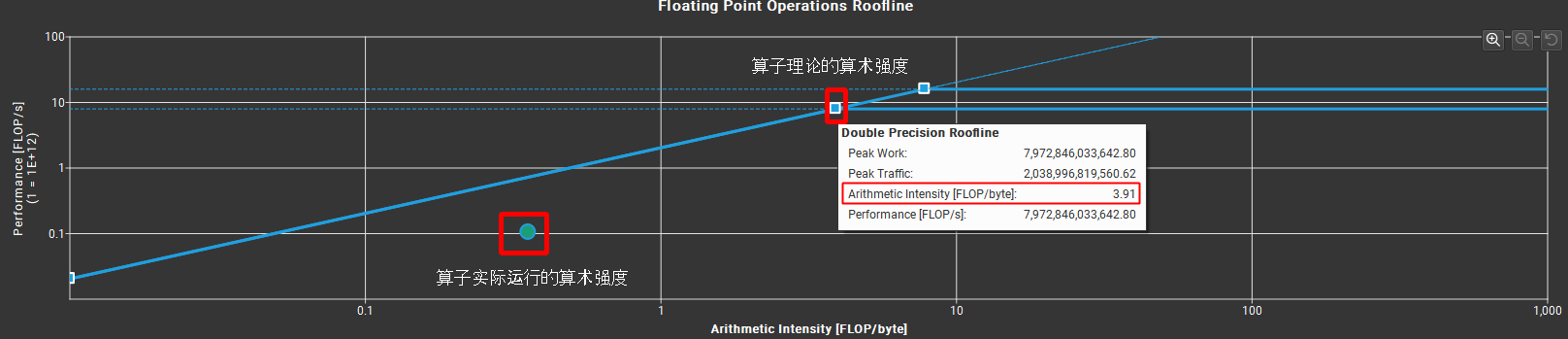 算术强度意味着什么?
算术强度意味着什么?
- 在 Ridge Point 左边,表示内存 Bound。算子延迟受访存带宽限制。
- 算子实际算术强度,距离屋顶的距离(下图白色的虚线),就是可以优化的空间
- 在 Ridge Point 右边,表示计算 Bound。算子延迟受计算能力限制。
疑问:
- 不同的算子理论算术强度都不一样,跟硬件理论的算术强度也不一样,这个差异的原因是什么?为什么这里 3.91 和硬件理论的 156 差距很大??
3.2. Compute Workload Analysis
比较关键的指标:
- Issued Ipc Active [inst/cycle] 0.84:表示平均每个 cycle,能执行的指令数,这个值越大,表明 GPU 执行指令的速度越快,这个值越小,表明 GPU 执行指令的速度越慢
 比如前面,我们知道 SM Frequency [Ghz] = 1.15那么:
比如前面,我们知道 SM Frequency [Ghz] = 1.15那么:
- A100: 0.84 instructions/cycle * 1.15GHz = 2.4725 instructions/s,表明在 A100 上,每秒执行的指令数是 2.47 个
特别注意:同一个算子,在不同的硬件上执行的时候,指令数是一样的,但是指令执行时的IPC以及指令执行时的运行频率,决定了最终指令的执行时间,也就是算子的耗时
3.3. Memory Workload Analysis
这个应该是 ncu 最有用的分析了
Memory Workload 分析能够支持看到 GPU 内部硬件结构的同道带宽
右上角有2个视角:
一个是看传输的大小:你可以计算传输量是不是和你理解的一致
一个是看传输的吞吐(吞吐大小决定了传输的延迟):看带宽是否达到了硬件的峰值
我们看一下 FNN1 的算子 ampere_fp16_s16816gemm_fp16_128x64_ldg8_f2f_stages_64x4_tn 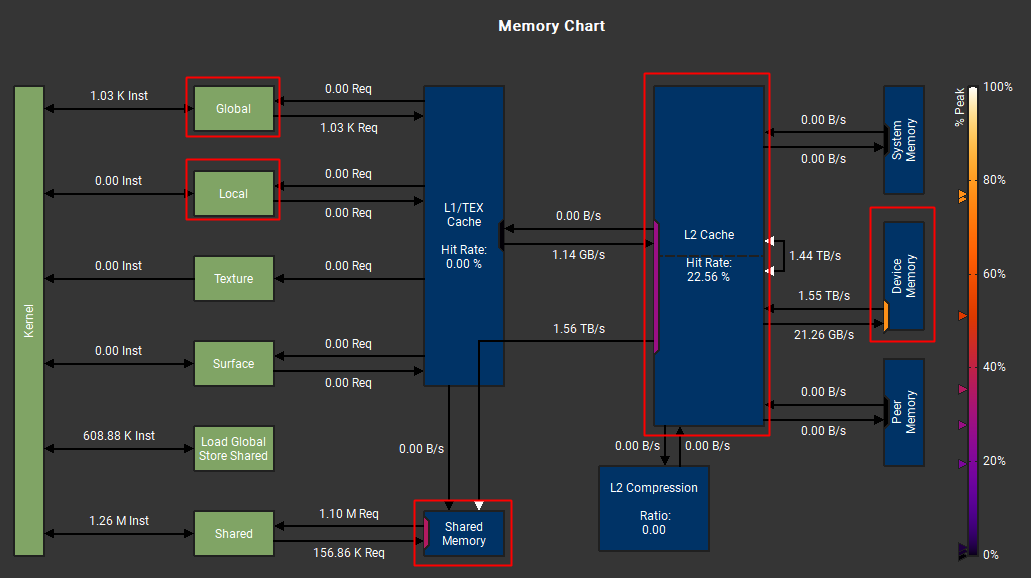
从官方文档:https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html#memory-chart-overview
我们得知,GPU存储结构是这样的:
- Global:全局内存,所有 thread 之间可见
- Local:本地内存,只有当前线程可见,主要保存线程的栈或者寄存器。Global和Local内存的访问速度是一样的。
- Shared:在SM上(located on chip),速度要远低于Local或者Global内存,一个CTA里(也叫Thread Block)的所有线程都可见
- L2 Cache:L2 缓存,A100的L2带宽理论上能到 6T/s,所以如果计算时数据都在 L2 上,计算性能就会好很多
- Device Memory:就是我们平常所说的 HBM,A100的访存带宽是2T/s
备注:
Central to the compute model is the Grid, Block, Thread hierarchy, which defines how compute work is organized on the GPU. The hierarchy from top to bottom is as follows:
- A Grid is a 1D, 2D or 3D array of thread blocks.
- A Block is a 1D, 2D or 3D array of threads, also known as a Cooperative Thread Array (CTA).
- A Thread is a single thread which runs on one of the GPU’s SM units.
3.3.1. Tranfer Size 视图
看 Tranfer Size 我们可以知道计算算子时:
- 读了多少数据
- 从哪里读,缓存命中率多少
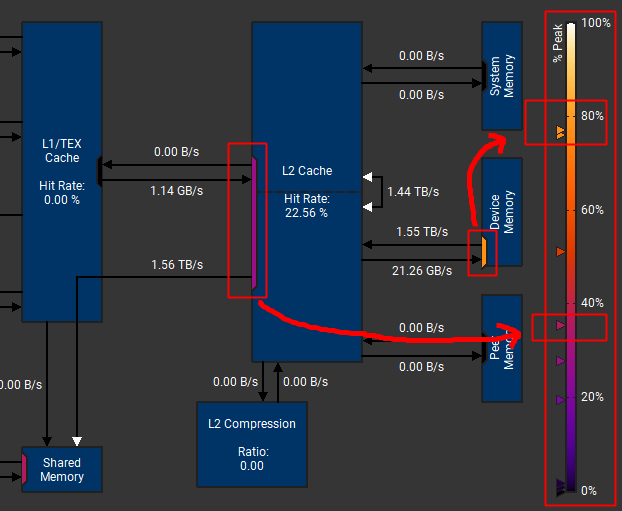
比如 FFN1 算子:
- 总共读取了 181.76M 数据
- 其中有 180.38M 的数据需要从 Device Memory(HBM) 上读取,但是166.79MB数据在L2上获取(这个数据感觉有点问题)
但是这个 L2 的 Hit Rate 22.56% 怎么算出来的一直没搞清楚,todo 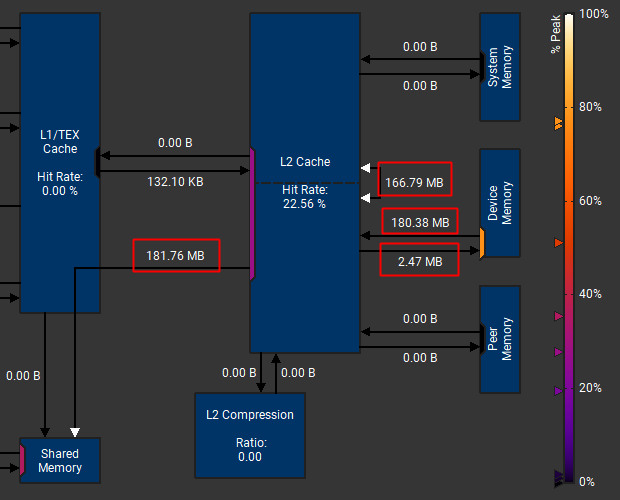
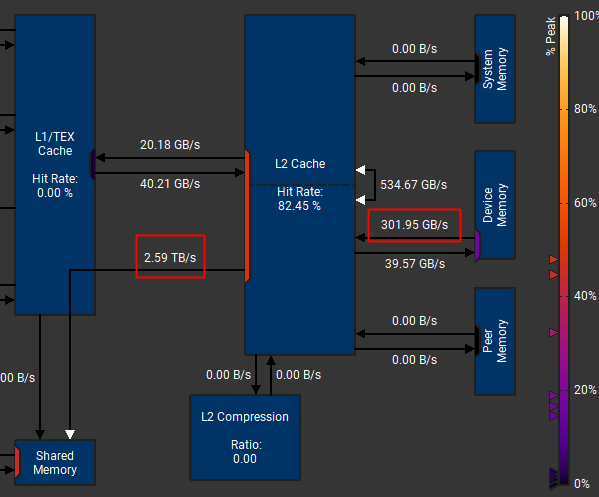
我贴一个之前好理解的算子的数据,像这个:
- Hit Rate 88.05% = (8.66G – 676.39M-1.41GB)/8.66G

3.3.2. Throughout 视图
吞吐视图可以帮助我们了解,GPU内部数据传输各个环节的带宽利用率,访存耗时取决于访存的带宽。这个图我们主要是看3个信息:
- L2带宽:这个一般是要比HBM带宽高很多的,除非命中率非常低,全都走HBM了
- HBM带宽:这个就是我们通常意义上说的,GPU的访存带宽
- Peak利用率:带宽的峰值,算子的理论算术强度主要是依赖这个计算出来的。(说明这个算子在这个硬件上,是可以达到这个峰值水平的)
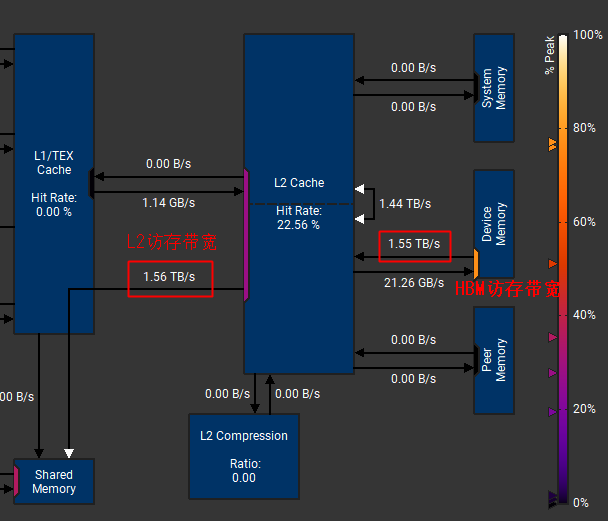
1)L2带宽 & HBM带宽
比如 FNN1 这个算子,访存带宽 1.55T,比较接近我们 A100 的理论值 2T/s但是由于L2命中率非常低,只有22.56%,基本所有数据都是要访问HBM了,所以L2带宽跟HBM带宽一样了,通常来说,如果L2命中率很高,L2带宽的理论峰值可以达到5T左右
但是我们有一个别的算子:ampere_fp16_s16816gemm_fp16_128x256_ldg8_f2f_stages_64x3_tn,不知道是算啥的
它的HBM的访存带宽就非常低,只有300GB/s,这种可能是存在优化空间的(跟算子的实现有关系)
有一些文章在研究这个问题:
2)Peak利用率
这个图还有另外一个信息,就是Peak利用率
比如 HBM 的访存带宽,1.55T/s,基本达到里理论带宽2T/s 的 78% 了,比较接近上限了,所以在图的这个位置
但是L2的带宽1.55T,相对L2的理论带宽5T,才30%
这个颜色有帮助我们分析性能退化的原因,是不是因为访存效率很低导致的矩阵运算的过程中,经常要做各种 padding,这种都是会增加无效的计算,影响访存带宽的效率
3.4. Warp State Statistics
这里主要是分析 SM 对 Thread 的调度上的一些性能,后面再看吧
todo(xxx)xx
现在看网上好像很少有使用ncu进行profile的文章,我自己尝试了一下发现报了个torch._dynamo.exc.Unsupported: Unsupported method call的错,想请问有什么解决办法吗?
ncu我们也常用,但是没见过你这个case,你这个错误看起来torch有些方法不支持?是不是torch和ncu版本不匹配?你强制降级了torch版本?