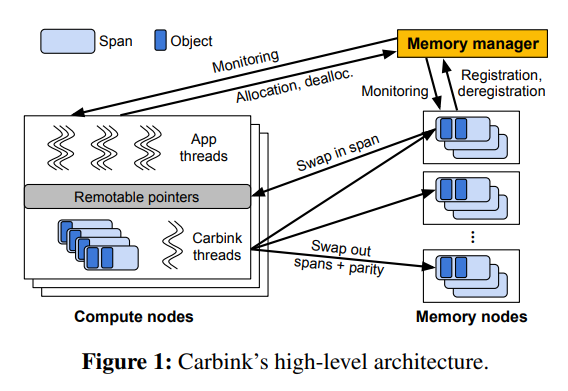
1. 概要
infiniswap 可以实现把一个机器的内存 swap 到另外多个机器上(1对多)
和其他实现相比,infiniswap 可以把开销做到很小,并且故障容错能力更强
- A transparent remote paging model for virtual machines @2008
- Swapping to remote memory over Infiniband: An approach using a high performance network block device @2005
- 还有一堆20+年前的论文(参考意义不大)
2. 架构设计
infiniswap 的组件其实就2个,非常简单:
- infiniswap-bd:一个虚拟的 swap 设备,其后端是远程内存
- infiniswap-daemon:管理本机对外提供的 remote memory(包括内存到虚拟地址的映射,等等)
这2个组件每个机器都会部署,类似于 daemonset
而且有个比较有意思的地方是,infiniswap 是去中心化的,它并没有一个中心式的管理组件(你看zombieland,中心式的管控组件就挺多的)
如下: