论文原址:https://www.cs.jhu.edu/~erfan/files/cts.pdf
cts 提出了一种优化长尾延迟的方法,通过改进 linux 内核默认的 cfs 调度器,引入线程调度机制
论文的一些要点:
- It has been proven that FCFS scheduling of threads leads to lower tail latency
- Experiments show that CFS policies lead to LCFS scheduling, aggravating tail latency
- CTS policies ensure FCFS thread scheduling, which yields lower tail latency.
- CTS enforces our policies while maintaining the key features of the Linux scheduler
- Experimental results show that CTS significantly outperforms the Linux scheduler
延迟敏感型的程序,通常有两种进程模型,一种是 thread-driven,另一种是 event-driven。前者很容易理解,起1个线程来服务一个请求,模型很简单。后者相对复杂一些,比如 libev,libevent 都是用来实现 event-driven 架构的基础库,通过 io 多路复用技术,将 io 线程和 worker 线程分离,io 线程专注数据转发,worker 线程专注业务逻辑处理
但是这个 io 线程很关键,如果数据 ready,但是得不到处理,会导致严重的长尾延迟。io 密集型的程序瓶颈不在 cpu,而是 io,CPU 上的时间片消耗是非常小的,远小于1ms,因而这种进程理论上应该优先获得响应
从这个结论推导出来,被唤醒的进程就应该优先调度,本质上就是 FCFS,先来先服务。但是 linux 内核默认的 cfs 调度器不是这样的,为了保证 fairness,内核会优先让所有的进程得到同等调度的机会(cfs 公平的弊端,有很多研究,这里就不细说了),而不是优先响应那些被唤醒的进程
为此,作者引入了 cts,一个在 cfs 上扩展的调度算法,本质上并没有替代掉 cfs 调度器,二是扩展了 cfs 的功能,在 cfs 的基础上,引入 FCFS
作者的思路很简单:
CTS is a 3-dimensional CPU scheduler.
- It leverages the default scheduler of Linux to perform the system-wide load balancing to distribute tasks among cores evenly (first dimension).
- At each core, CTS lets the default Linux scheduler to choose a process that one of its threads must be executed next (second dimension).
- Once the next process is selected, the CTS thread scheduler chooses a ready thread of the chosen process for execution (third dimension).
先简单说下原理,还是依赖 cfs 来做 core 之间的 load balance,还是依赖 cfs 来选择待调度的 process(注意是 process,而不是 task),当 cfs 确定 process 之后,cts 开始干活了,由 cts 来决定最终执行这个 process 下的哪个 thread,所以本质上 cts 是一个 process 内的 thread-scheduler
如果你看过 Linux 内核代码,应该知道 cfs 的调度单元 sched_entity 是线程而不是进程,内核其实是看不到进程这个概念的。进程是操作系统领域,为了描述资源而抽象出来的一个概念。那 cts 是怎么依赖 cfs 来决定最终调度哪个 process 呢?答案很简单粗暴
At each scheduling decision, once the default Linux scheduler chooses the next process, CTS finds the first thread of the process to be executed next,
再来说说 FCFS 的实现
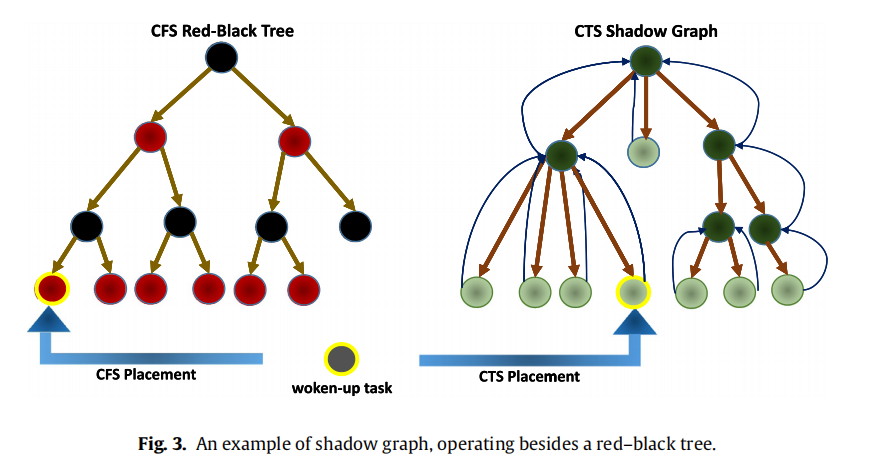
作者设计了一个 shadow-graph,用来维护 FCFS 信息,这个 shadow-graph 和 cfs 的 rb-tree 是同生命周期的,维护的 task 内容也完全一致。唯一的区别就是 shadow-graph 不再按照 vruntime 来排序,vruntime 是 cfs 能够保证公平性的一个很关键的设计。FCFS 很简单,谁先唤醒,谁就在队列头部,谁就应该更优先得到调度
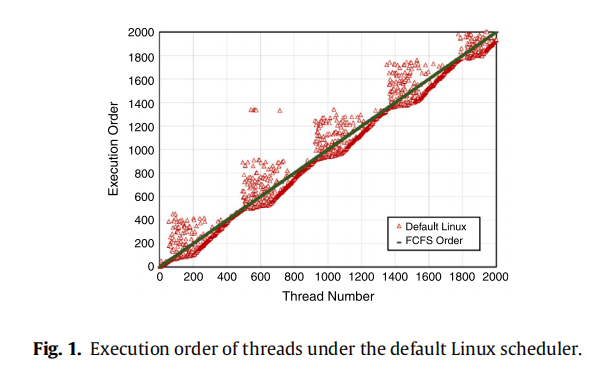
理论上来说,FCFS、LCFS 等这些调度算法,其实平均调度延迟肯定是一致的,但是 FCFS 每个进程都会里平均延迟更近,所以它的方差会小很多,而 LCFS 的方差就会很大。长尾本身就取决于数据的分布,和方差有莫大关系。因而 FCFS 一定会比 LCFS 有更好的长尾延迟
task 进出 cfs_rq,都会同时进程 cts shadow-graph,并且 shadow-graph 获取 first-process 的时间复杂度是 o(1),性能不是问题
cts 怎么实现 FCFS 调度算法呢?当 linux 内核按照 cfs 选出一个待调度的 task 时,这个时候 cts 开始起作用,它会先找到这个待调度的进程,所属的父进程,然后从 cts shadow-graph 里面找到当前进程下最应该优先被调度的那个 task,来替换 cfs 的调度结果
但是一般来说,直接改变 cfs 的调度结果,必然会打破公平性,会引入很多其他非预期的问题。论文作者也提出了一种比较优雅的解决方案(loan – borrow time)
最后是 cfs 默认调度算法和 cts 调度算法的效果对比