前面我们学习的,回归和分类,都是监督学习中最经典的学习方法。
监督学习是从有标记的训练数据中推导出预测函数。有标记的训练数据是指每个训练实例都包括输入和期望的输出。一句话:给定数据,预测标签。
而无监督学习则是从无标记的训练数据中推断结论。最典型的无监督学习就是聚类分析,它可以在探索性数据分析阶段用于发现隐藏的模式或者对数据进行分组。一句话:给定数据,寻找隐藏的结构。
比如在分类问题中:
假设我们有一堆样本数据,并且知道每个数据的所属分类,那么通过监督学习,我们就能知道数据的特征和分类之间的关系,并以此建立数学模型。当输入一个新的数据时,我们就能够按照模型预测分类的结果。这就是监督学习
但是更多时候,我们可能是有一堆样本数据,我们甚至不知道这些数据到底可以分成几类。通过无监督学习算法,我们甚至可以自学的尝试为这堆数据分类,并找到其中隐藏的数学模型。这个就是无监督学习
无监督学习算法的应用场景,在生活中非常常见,Ng 在 13 – 1 – Unsupervised Learning_ Introduction (3 min).mkv 中举了一些例子
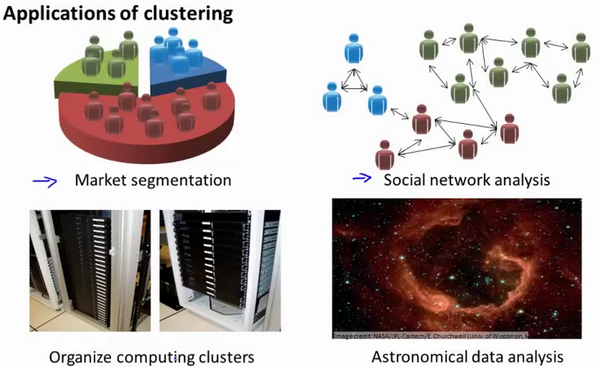
常见的无监督学习算法:
- 聚类:层次聚类、
均值聚类、高斯混合模型
- 降维:主成分分析 PCA
- 话题分析:潜在语义分析 LSA、概率潜在语义分析 PLSA、潜在狄利克雷分配 LDA
- 图分析:PageRank