这是2篇非常经典的微架构层面的性能分析相关的材料,作者提出了一套自顶向下的性能分析方法论
微架构的性能分析是一件很困难的事情:
- 复杂的微架构
- 应用/负载的多样性
- 难以处理的数据
- 时间、资源、优先级等其他更要命的约束
自顶向下分析法的目的就是要从顶层问题出发,层层剖解,直至找到瓶颈所在
1. 现代CPU微架构
CPU主要分为3个部件
- front-end,也叫前端,主要的功能就是用来加载指令,所以前端又会包含指令缓存、BPU等基础组件
- back-end,也叫后端,主要的功能就是执行指令,后端包含各种执行单元,例如MMX/SSE/AVX等等
- L1 & L2 cache,缓存,用来加速指令或者内存的数据访问
指令又包含两种,一种是计算指令,一种是访存指令(比如访问内存)
一个指令被执行的完成流程如下:
- 指令首先被加载进指令缓存(也可能是预加载)
- 转换成CPU微码,发送给back-end
- 等待被调度到具体的执行单元
- 指令执行:根据是否是访存指令还是计算指令,做出后续不同的行为

2. 自顶向下分析法
这个方法论其实很有意思
performance bottleneck 的本质其实还是说资源产生冲突了,导致指令在被 pending 了,更专业一点的术语叫 stall。你仔细想想这个问题其实还真是这样的,微架构层面会发生 stall 的地方其实是非常多的,我们就拿上面那个图来说说
首先是 front-end,什么场景下会 stall?front-end 的核心功能就是加载指令,stall 有两种情况:分支预测失败,或者说指令不在缓存里面,这很关键。所以我们通常说,如果一个代码分支预测失败率很高,那性能一定是很差的,linux kernel 代码上千万行,内核为了优化各种分支预测的性能问题,会显式的使用 likely 宏来告诉编译器,当前分支是会有极大概率走到的
https://kernelnewbies.org/FAQ/LikelyUnlikely
然后就是 back-end,负责指令执行的地方,可以 stall 的地方就更多了
现代CPU都是多流水线架构的,肯定不是一条一条指令的串行执行,都是流水线批量执行,那就一定会遇到指令执行单元不够用的情况,比如在 scheduler 队列里长期 pending
另一种情况是访存,如果数据不在 L2 & L3 cache 里面,那么 CPU 必须把数据从内存中读取上来,访问内存本来就要比访问 cache 慢好几个数量级,这段时间指令就必须长期 hold 住执行单元,产生 stall
访问内存又会带来更复杂的问题,Numa 架构,内存总线带宽等,会成为访存性能的瓶颈
问题的结构似乎已经很清楚了,下面这个就是自顶向下分析法的核心思想
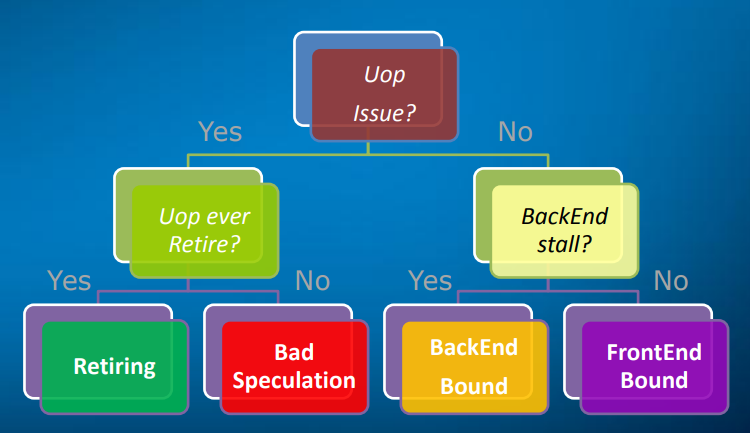
2.1. Top-down Hierarchy
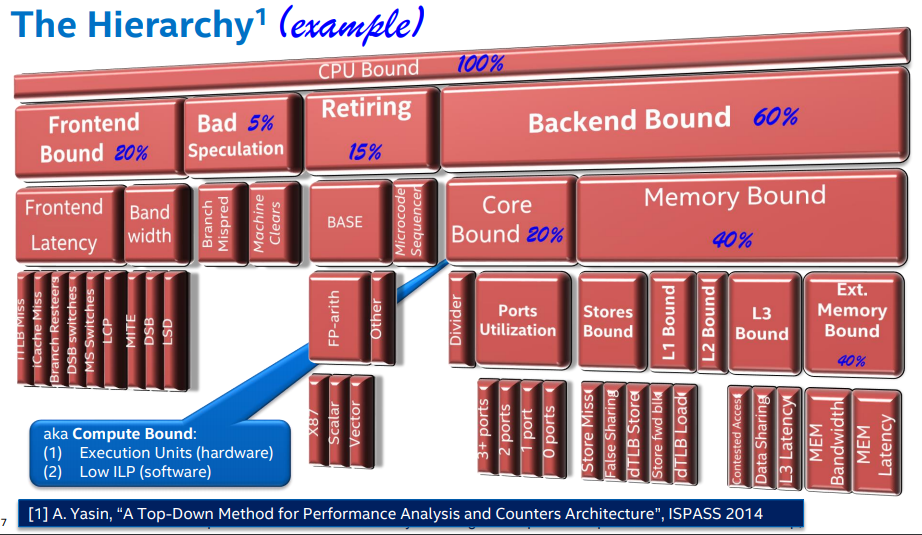
更具体一点的,我们通常所说的 CPU Bound,从微架构层面,可以拆解的非常细致,挑几个关键的说一下
Frontend Bound 是指-指令加载延迟,Bad Speculation 是指分支预测失败(代码写的烂),Retiring 是指真正有效的 CPU 指令执行时间,Backend Bound 是指指令执行延迟
Core Bound 其实是更像我们通常说的 CPU Bound,这种延迟的产生主要原因是流水线 并行+ 指令执行单元不够,冲突,导致的,CPU 指令长期处于等待执行的状态
Memory Bound 就是访存延迟,又分为 L1 & L2 Bound,这个一般都不是问题,L3 Bound 主要是因为 L3 cache miss 引起,Ext Memory Bound 影响比较大,比如跨 Numa 访存、内存总线带宽阻塞,等等
2.2. Top Level Equations
实际问题分析过程中,我们把整个 profile 结果能识别到顶层的4大类就够了,足以定位大部分问题所在,这4类就是 Frontend-Bound,Bad Speculation,Retiring,Backend Bound
这个怎么计算呢?很复杂,依赖 perf 的各种底层 uarch 性能指标
Front End Bound
– The front end is delivering < 4 uops per cycle while the back end of the pipeline is ready to accept uops
• IDQ_UOPS_NOT_DELIVERED.CORE / (4 * Clockticks)
Bad Speculation
– Tracks uops that never retire or allocation slots wasted due to recovery from branch miss-prediction or clears
• (UOPS_ISSUED.ANY – UOPS_RETIRED.RETIRE_SLOTS + 4INT_MISC.RECOVERY_CYCLES) /(4 Clockticks)
Retiring
– Successfully delivered uops who eventually do retire
• UOPS_RETIRED.RETIRE_SLOTS / (4 * Clockticks)
Back End Bound
– No uops are delivered due to lack of required resources at the back end of the pipeline
• 1 – ( FrontEnd Bound + Bad Speculation + Retiring )
不过这里有个问题,每一代内核和 CPU,对于各种场景下的 stall 命名都不太一样,如果要精确到具体每一代 CPU,perf 的性能指标具体叫啥的话,只能查 Intel 使用手册了:https://software.intel.com/content/www/us/en/develop/documentation/vtune-help/top/reference/cpu-metrics-reference.html