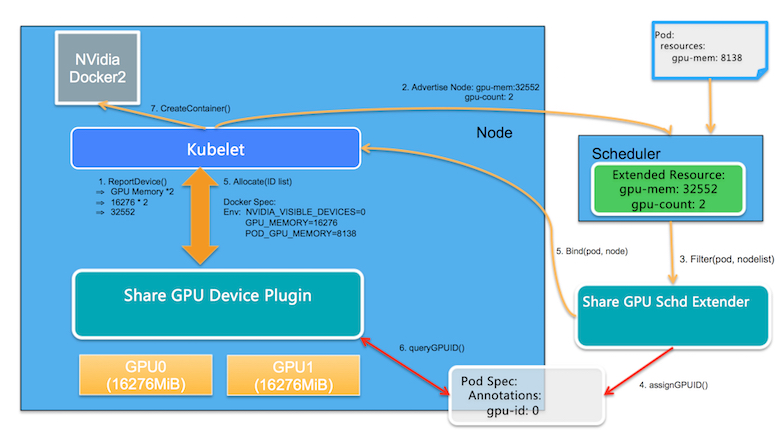
RunD – A Lightweight Secure Container Runtime for High-density Deployment and High-concurrency Startup in Serverless Computing
rund 是阿里提出的一种新的轻量级容器运行时技术。
不过目前从论文内容来看,更多是一些技术点的优化,而不是架构层面的创新
1. 设计目标
实现 serverless 场景下,pod的高密度部署、高频、高速启动
高密度部署:随着机型规格越来越大,比如 AMD milan 就有256核,可以部署数千个 pod
高频:faas 和 batch job 等负载,每天上百万的实例创建量,上亿次系统调用
高速:faas 场景的毫秒级启动,极致弹性
2. 问题分析
kata 容器的技术栈:

启动一个 kata 容器,首先需要通过qemu(或者其他hypervisor,比如fire cracker)拉起一个虚机,然后还需要再虚机内启动一个agent,来实现完整的oci语义
基本过程如下:

2.1 并发启动的开销
(1)在准备容器rootfs的可写层时有很长的耗时:同时启动200个kata container,准备rootfs需要耗时207ms,会产生4500iops和100MB/s的IO带宽,带来很高的cpu overhead
(2)同时启动多个kata containers时,涉及到host侧cgroup的创建及维护,在内核层面,凡涉及到cgroup 操作,需要持有全局粒度的自旋锁,导致cgroup 的创建及维护是一个串行过程
2.2 高密部署的瓶颈
(1)虚机(guest系统 + kata-agent + guest kernel)耗损
容器不是虚机,但是实现安全容器就必须依赖虚机。容器的规格一般都是很小的,比如内存100m 0.1vcpu,但是这个规格对虚机来说太小了,都起不来。所以为了能开一个100m的容器,你就得把虚机开到200m甚至更大,这就产生了 overhead
对于kata-qemu,一个内存规格为128MB的kata-containers,其内存overhead可以达到168MB;当部署密度从1提升到1500时,平均每个内存规格为128MB的kata-containers,其内存overhead 仍然会有145MB。

对于小内存规格的kata容器,guest kernel image所占内存占用了很大的比重。AWS数据:47% 的function computer的内存规格时128MB,Azure数据:90%的应用内存规格小于400MB。
(2)rootfs 内存耗损
rootfs基于块的主流解决方案在Host和Guest中生成相同的Page Cache,导致重复的内存开销。