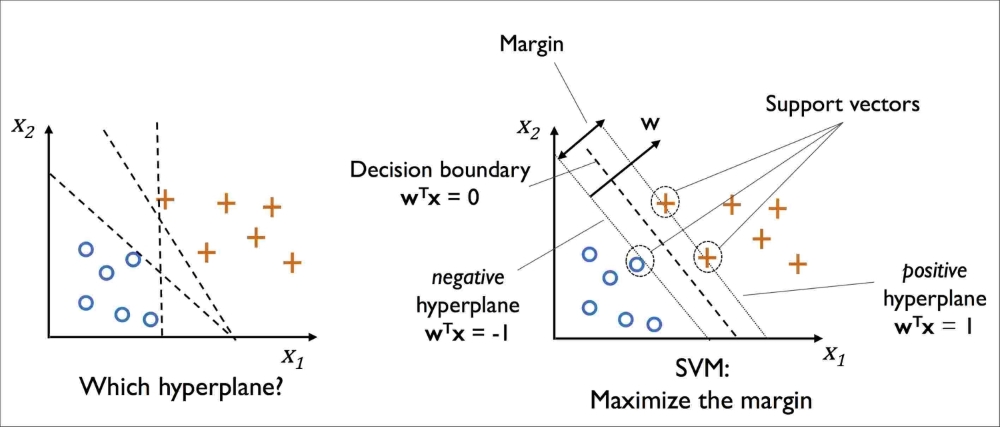
主成分分析(PCA)是最常见的降维算法,通常用于数据压缩以及噪音过滤
比如我们可以通过PCA将100维的向量最后用10维来表示,那么压缩率为90%,同时还可以保证数据的特性损失尽可能的小
1)PCA算法流程
在详细展开讲之前,先了解一下几个基本数学符号的定义:
x^{i} 表示第i个样本数据(这个数据是一个N维向量)
x_{j}^{i} 表示第i个样本的第j个特征
x_{j} 表示由所有样本数据的第j个特征变量组成的一个向量
了解这些数学符号的定义非常重要,否则后面的推导公式很容易混乱
假设我们有一个n维的样本数据集 D = (x^{(1)}, x^{(2)}, ..., x^{(m)}),其中每一个数据都是n维的 x^{(i)} = \{x_1^i, x_2^i, ..., x_n^i\},我们要把维度从n维降到k维:
- 对所有样本进行归一化 x^{(i)} = x^{(i)} - \frac{1}{m} \sum\limits_{j=1}^{m} x^{(j)}
- 计算协方差矩阵(covariance matrix)XX^T,其中 X 的定义非常重要
- 计算协方差矩阵XX^T的特征向量(eigenvectors),通常用SVD分解,得到 [U, S, V]
- 从U中选取前k个最大特征值对应的特征向量,组成一个新的特征向量矩阵U_{reduce}
- 对所有样本,求的新的降维后的样本,z^{(i)} = U_{reduce}^T * x^{(i)}