Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache
1. 问题
模型的架构:
- QKV Linear layer
- Multi-Head Self-Attention Mechanism, or the attention module
- FNN,Feed-Forward Neural Network
超长文推理的挑战,2k -> 256k ?
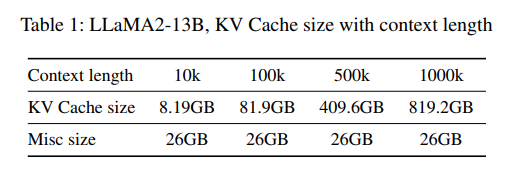
有2个:
- 不同的层对显存的需求差异很大(注意力层的显存和输入输出是成比例的,但是其他层不是),这就限制了并行的效率(类似木桶效应??)
- KV cache 的大小不可预估,显存容量不可规划
这2个问题,最终也极大的限制了超长文推理的效果
2. 解决思路
把 KV cache 的存储和计算从推理引擎里卸载出来,搞成分布式的,背后是一个池化的显存池
- 提出了一个分布式的注意力计算方法 DistAttention,decoupling of KV Caches’ computation fromthe standard transformer block
- 基于 DiskAttention 的思想,实现了 DistKV-LLM,一个高效的、可扩展的、一致性的分布式 KV cache 服务,能够有效的池化整个数据中心的显存、内存资源
DistKV-LLV 有2个核心组件:
- rManager:提供一种显存的抽象层 rBlocks,可以使用整个数据中心的显存和内存资源
- gManager:用于管理 rBlocks 的一致性和全局显存协调
3. 方案架构
3.1. DistAttention
一种新的分布式的注意力计算方法简单来说,把KV cache的存储和计算,分成一小块一小块的 MA 的存储和计算,每个 MA 是在一个远端的 GPU 上存储和计算的,最后结果可以 merge,不影响准确性(这个数学上怎么证明准确性就不用管了)
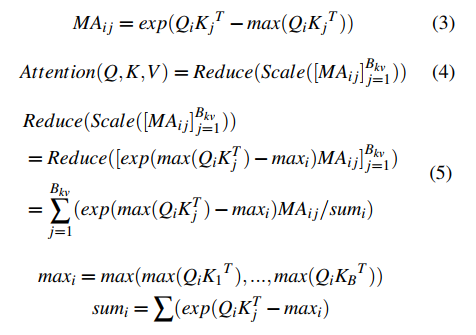
这里面最主要的就是2个函数:
- DistAtten
- ScaleReduce
DistAttn 算子专为分布式注意力计算而设计,结果由 ScaleReduce 算子合并以产生最终结果同时,为了降低分布式计算的同学延迟,使用 NCCL + RDMA 来实现跨GPU的张量传输
3.2. DistKV-LLM
3.2.1. The rBlock and rManager
每个LLM服务,都标配一个rManager,专门管理rBlock的分配rManager 提供一组标准的接口:即可以接受来自本地的内存分配,也可以接受来自远端的内存分配可以分配给远程实例的rBlocks是有限的,根据实际测试来决定(猜测:可能是性能考虑??)
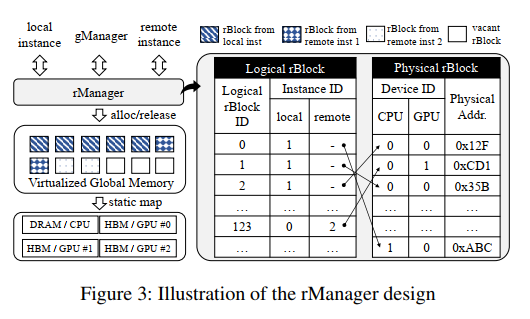
3.2.2. The gManager
gManager 维护全局的租约信息,每个rManager都会定期通过心跳向gManager汇报当有实例显存不足的时候,按照下图12345流程,从其他实例上借用显存gManager在调度的时候会考虑一些原则:
- 就近分配(减少通信成本)
- 最大分配(尽可能少拆)
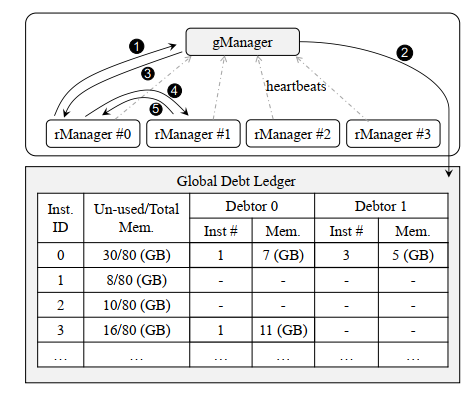
如上图所示:
- ins-0:负载很轻,空闲内存借给了ins-1和ins-3
- ins-1:长推理,从ins-0和ins-3借了18G显存
- ins-2:既不借给别人,也不借别人的
- ins-3:借给了ins-1一部分显存
xx
3.3. DGFM 碎片管理
xx
4. 性能评估
环境:4机器,32GPU,没台机器8个A100(80GB显存)模型:支持 GPT,LLaMA,BLOOM,LLaMA2