内容
隐藏
1. Measuring the Mismatch: The vllm-kl Metric
\small{\mathbb{E}_{s\sim d_{\textcolor{red}{\pi^\text{vllm}_\theta}}}\left[\text{KL}\left(\textcolor{red}{\pi^\text{vllm}_\theta}\left(\cdot|s\right),\textcolor{blue}{\pi^\text{fsdp}_\theta}\left(\cdot|s\right)\right)\right] = \mathbb{E}_{s\sim d_{\textcolor{red}{\pi^\text{vllm}_\theta}},a\sim {\textcolor{red}{\pi^\text{vllm}_\theta}\left(\cdot|s\right)}} \left[\log\left(\frac{\textcolor{red}{\pi^\text{vllm}_\theta}(a|s)}{\textcolor{blue}{\pi^\text{fsdp}_\theta}(a|s)}\right)\right],}但是代码用的是 kl3 散度
kl = \frac{\pi_1}{\pi_2} - log(\frac{\pi_1}{\pi_2}) - 1rollout_log_probs = batch.batch["rollout_log_probs"] # pi_vllm actor_old_log_probs = batch.batch["old_log_probs"] # pi_fsdp response_mask = batch.batch["response_mask"] log_ratio = actor_old_log_probs - rollout_log_probs vllm_k3_kl_matrix = torch.exp(log_ratio) - log_ratio - 1 vllm_k3_kl = masked_mean(vllm_k3_kl_matrix,response_mask)
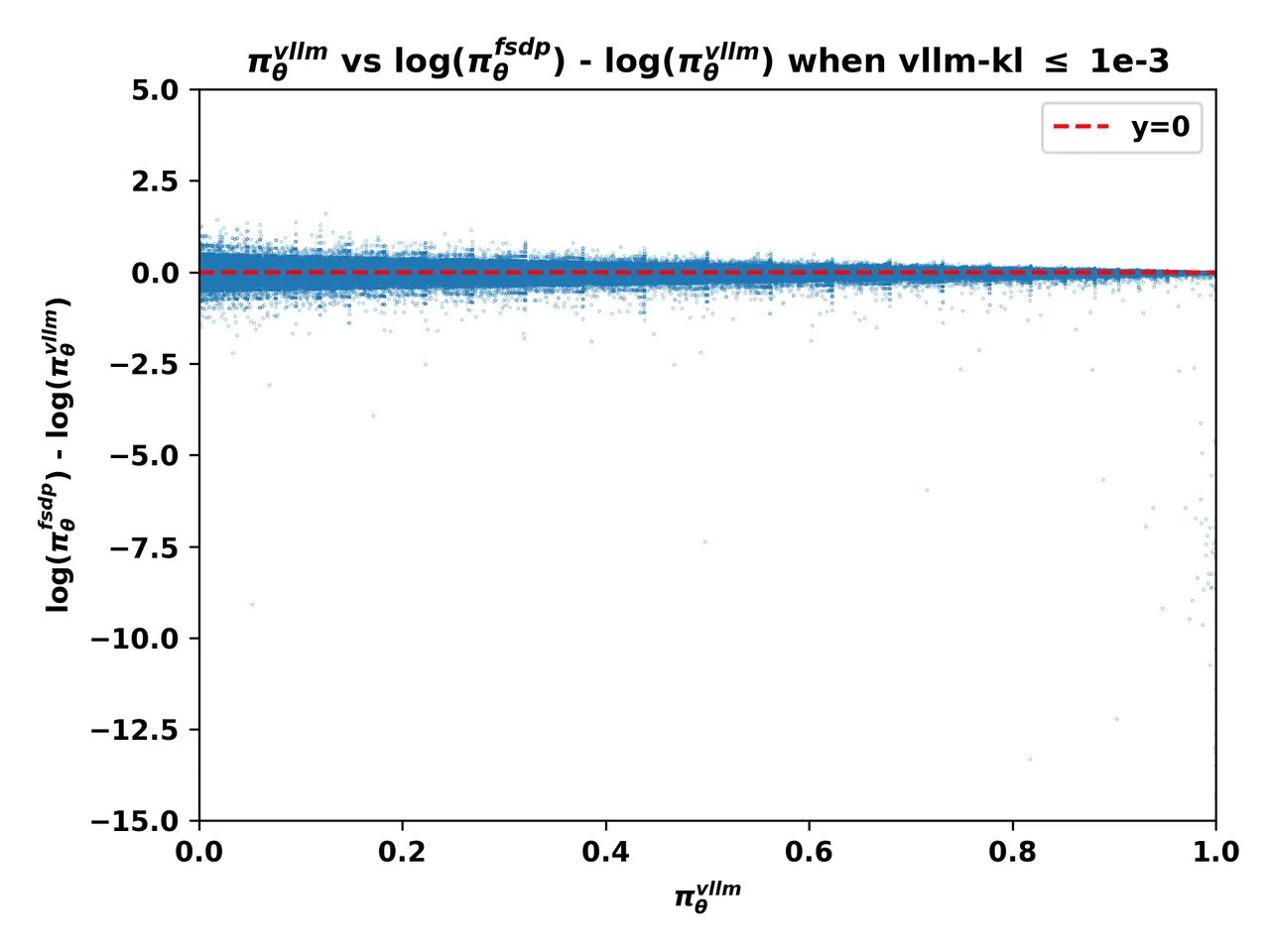
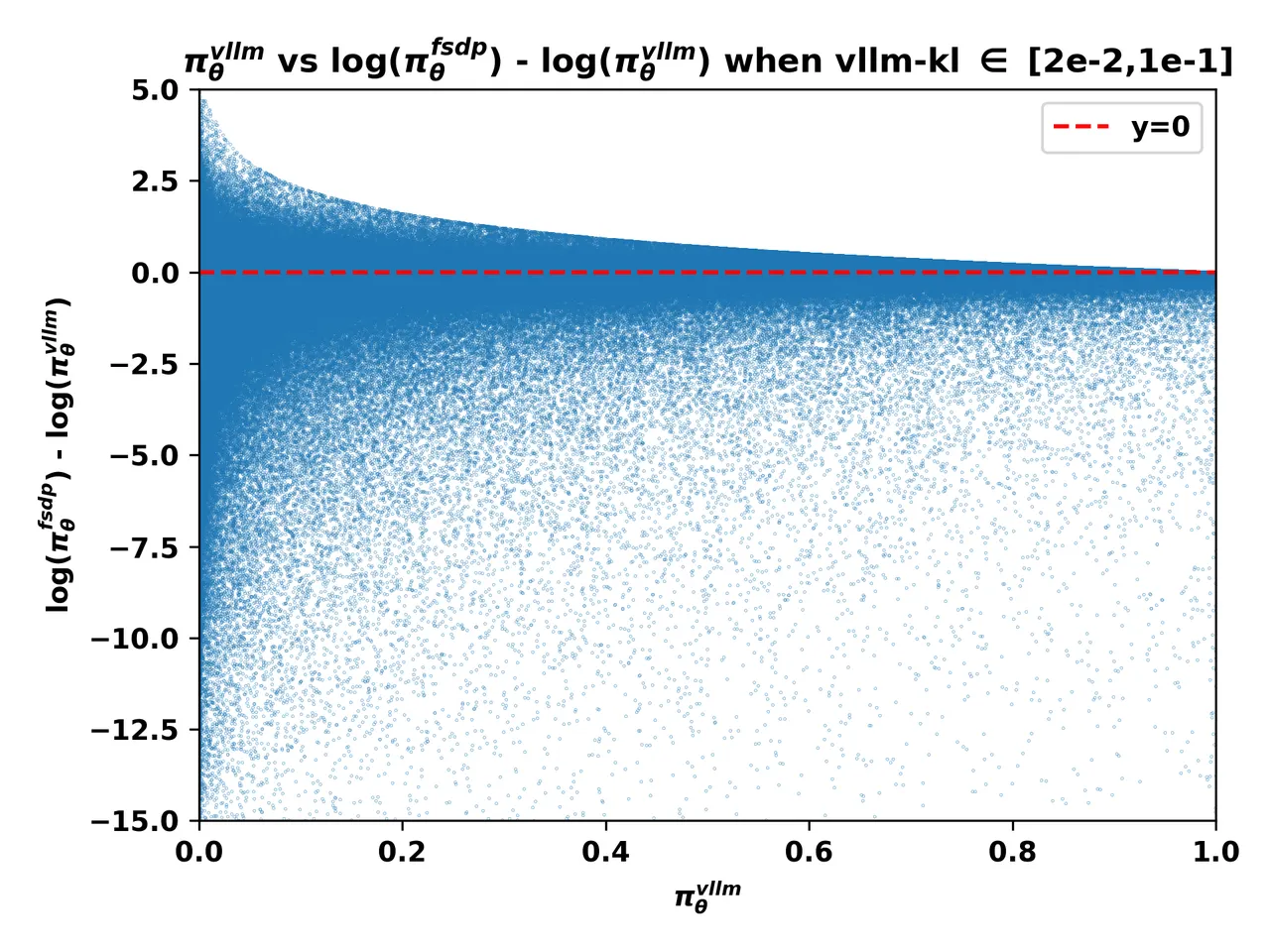
2. The Smoking Gun: The Low-Probability Token Pitfall
这个洞察意义其实不大,这个相关性不需要通过数学分析来找到这种洞察,vllm-kl很小,从数学上就能直接推导出 \frac{\pi_{fsdp}}{\pi_{vllm}} 会很发散
不过这里有一个重要的洞察是:当熵很大的时候,fsdp的log_probs要比vllm的log_probs小
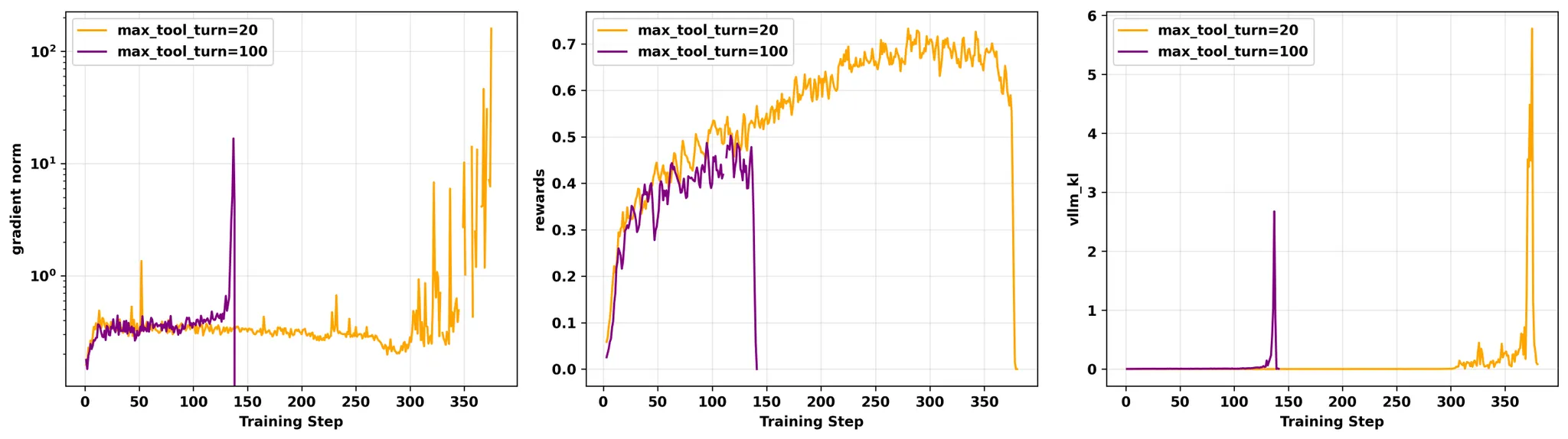
3. More Tool Calls, More Training Instability
对于没有见过的上下文,大模型是很难学习到这之间的相关性的
猜测:
传统的工具调用,工具生成的结果,在训练阶段会被 mask 掉。这样会导致RL过程中,大模型会强制计算2个不想关片段的相关性,但是可能这个相关性在现有大模型的能力里就是没有的。因此训练很容易崩溃。
工具调用的RL可能需要一个新的范式。
4. The Environmental Factor: The Critical Role of Hardware
xx
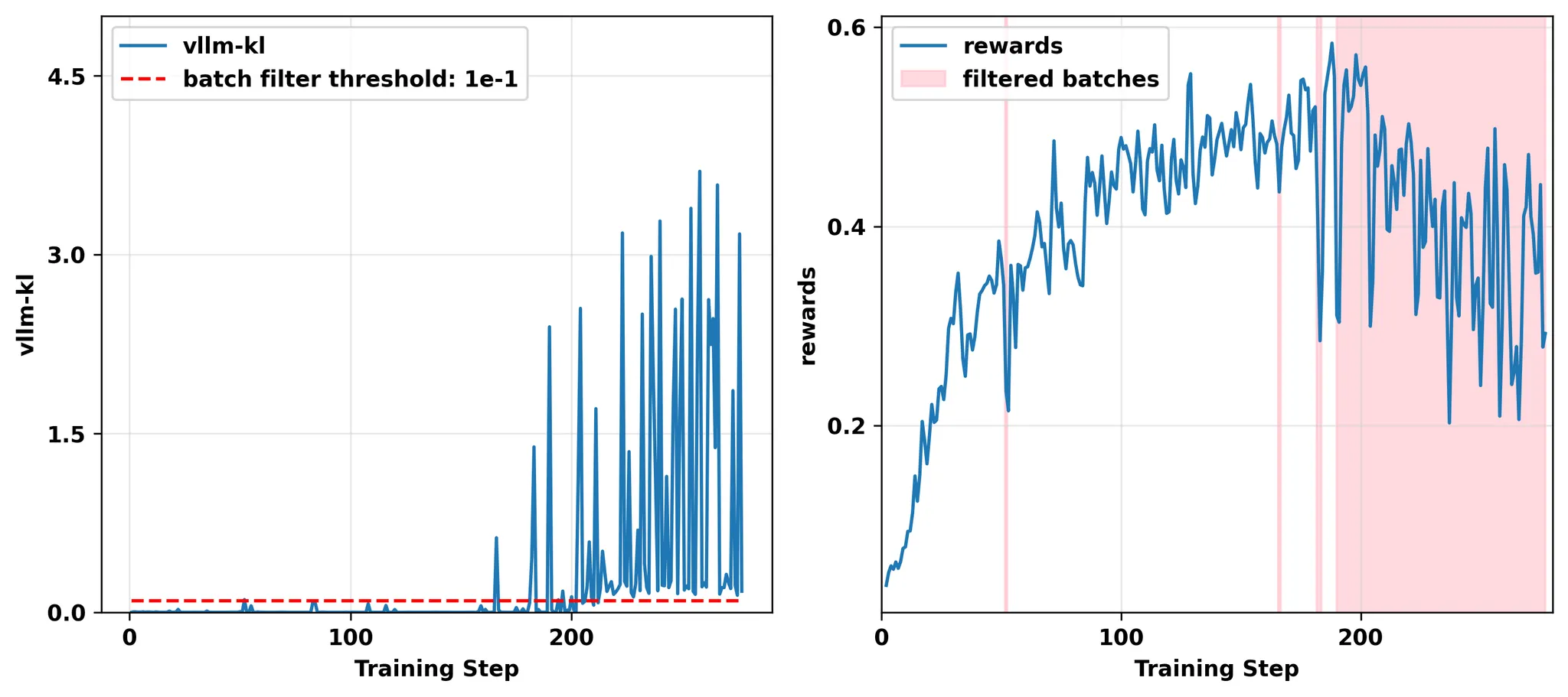
5. The Mismatch is Not Static: A Vicious Cycle Driven by Optimization
如果vllm-kl > 0.1,过滤掉当前的batch数据,不更新模型权重。
本质上等价于 gspo。
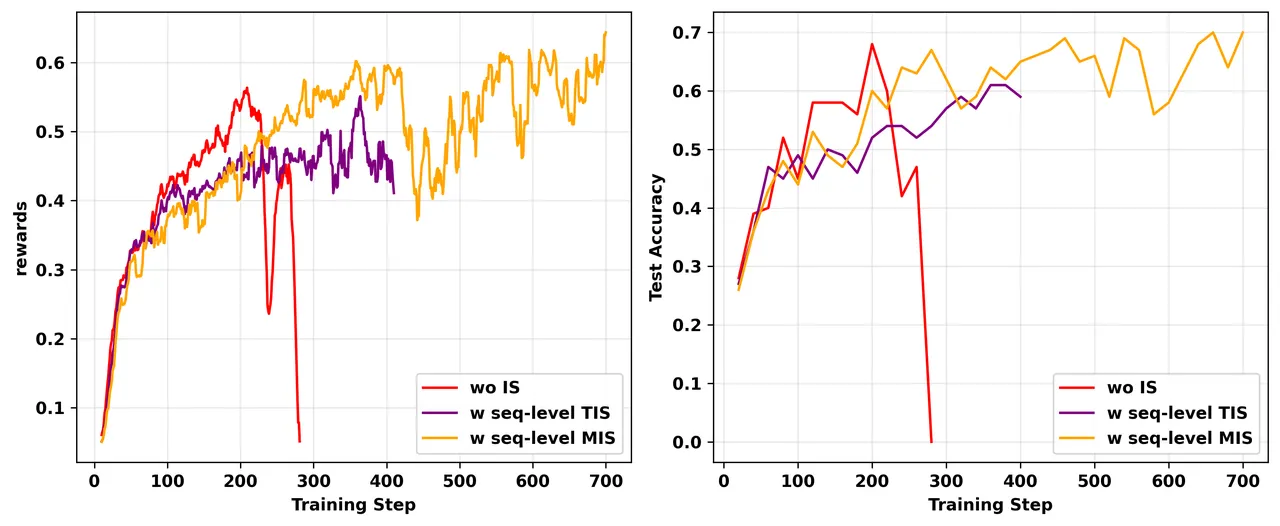
6. Masked Importance Sampling (MIS)
原文 4.2.1 首先从数学上证明了 token-level 的重要性采样是一个有偏估计,原因有2:
-
分布的误差是由2方面引入的:状态空间的偏差和动作空间的偏差,token-level IS只修正了动作空间的偏差,没有修正状态空间的偏差(疑问:但是token的概率其实隐含了状态空间的概率,所以理论上也一定程度的修正了状态空间的误差)
-
奖励是基于 fsdp 策略空间的,而不是 vllm 动作空间的,所以这里也有误差
作者提出了 MIS 策略:对于 seq 的重要性误差超过 C 的,直接 masked 掉,不参与梯度更新
这个做法和 GSPO 是类似的,和 GSPO 不同的是,MIS保留了GRPO的token-level梯度计算方式,而GSPO的token-level梯度公式不一样了。
如下:
gspo的梯度公式可以看gspo的论文
效果:
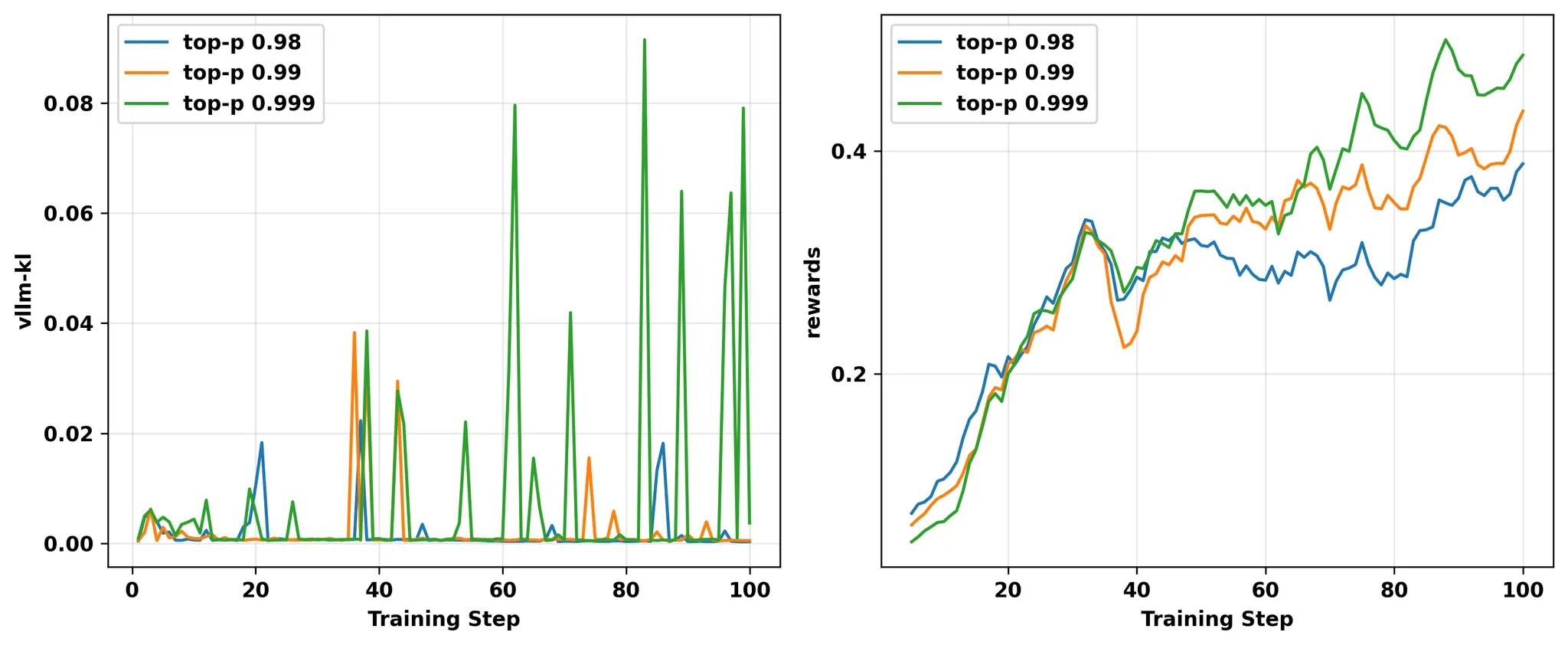
7. Top-p Sampling
这个更感觉像是个反例
top-p越大,vllm-kl越大,但是 reward 反而更好了。。。
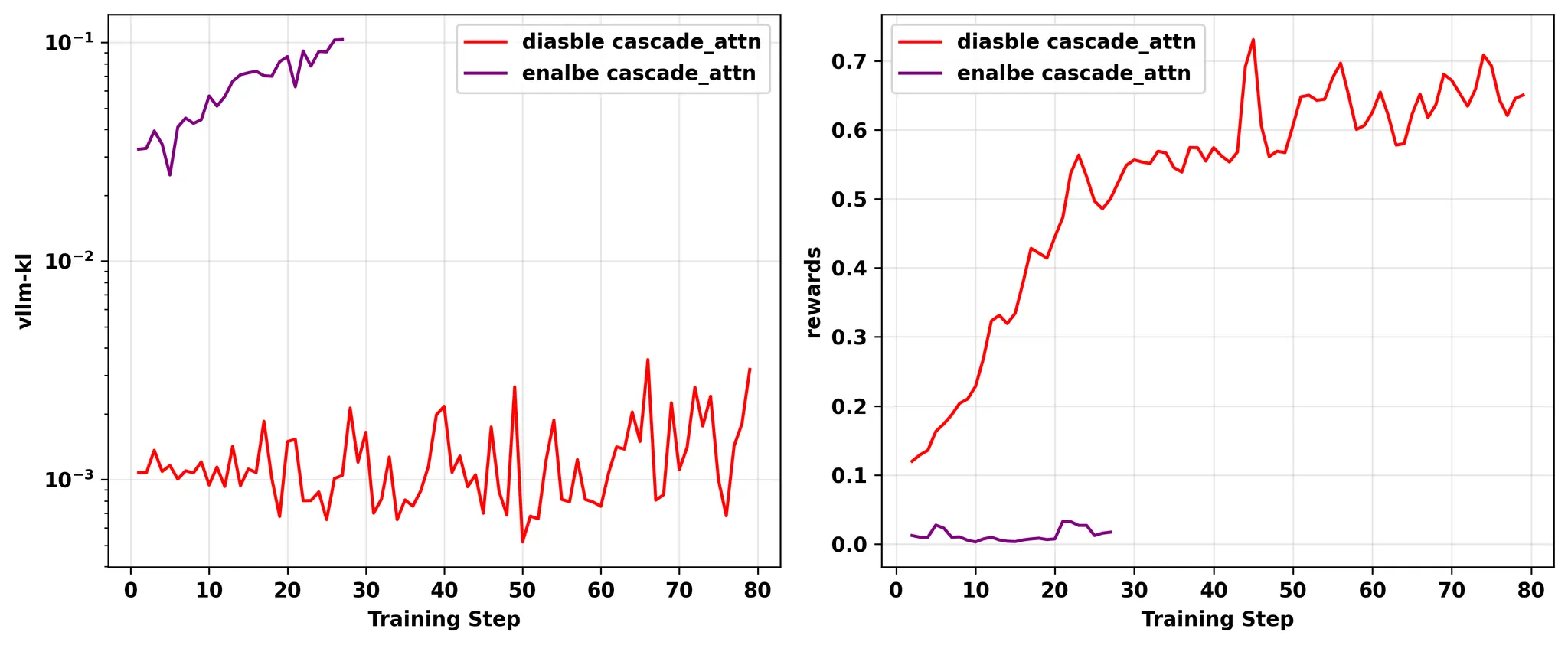
8. Diable Cascade Attention in vLLM
这个问题根源是 flashattention2 的一个bug,在a100和L20这种型号的GPU上,大batch size下会触发split-kv,这个split-kv操作会导致一个LSE错误。
这个bug已经被修复了: