最近在研究大模型的强化学习,整理下相关的算法基础,了解一下当前主流强化学习算法的一些改进思路
1. 目标函数
1.1. 预训练
自回归模型的目标是预测序列中的下一个词元,也是使用交叉熵损失:
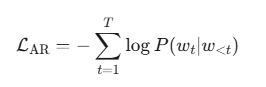
其中:
-
T 是序列长度。
-
w_t 是时间步 t 的真实词元。
-
w_{<t} 是时间步 t 之前的所有词元。
-
P(w_t | w_{<t}) 是模型预测给定历史词元后,下一个词元为 w_t 的概率。
1.2. 强化学习
最大化目标函数(最大化优势) = 最小化 -目标函数
所以强化学习把 loss 定义为 = - si(θ) * adv
典型目标函数:
(1)PPO
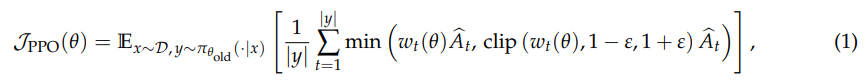
(2)GRPO
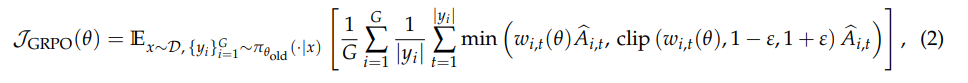
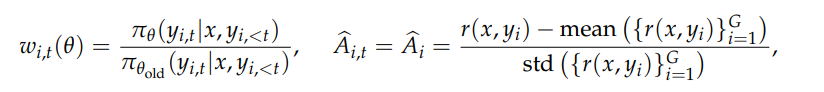
其中:
- G 表示同一个 prompt 的G条样本答案
- y_i表示第几条样本,|y_i|表示向量的长度的,也就是 token 数,但是实际上这里面loss是求平均还是求和,有很多算法:token-mean,seq-mean-token-sum,seq-sum-token-mean
GRPO 计算的是 token 粒度的平均 loss
(3)GSPO
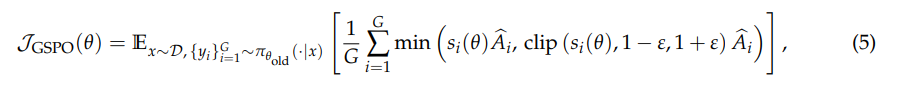
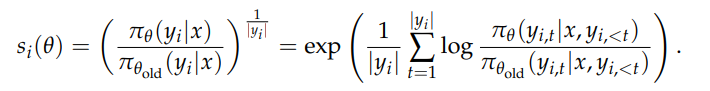
优势计算和 GRPO 一样
GSPO 计算的是 seq 粒度的平均 loss
(4)DAPO
xx
(5)BAPO
xx
和预训练不一样,强化学习是基于 reward 而不是交叉熵,token-level-reward
上面公式,除了clip的目的主要是为了防止模型训崩,loss计算的核心是重要性系数和adv优势。