比较有价值的点:论文提出了一种新的,低成本的,在离线混部实现方式
1. 问题背景
1) At low loads, most of the GPU memory is allocated but not used, occupying the GPU memory and preventing it from being used by other services;
显存已分配未使用,其他服务也用不了 -> 论文提到了,他们用这个技术来做离线混部。
2) At high loads, due to the GPU memory allocation threshold set by the inference engine, up to 10%-20% of the GPU memory remains unused and idle. Hence, the current GPU memory management is inefficient;
由于推理过程存在不确定性,所以通常会预留一部分显存,导致 10%~20% 的浪费
3) The prefill and decode stages of the inference process have significantly different demands on GPU memory
prefill 和 decode 阶段的显存需求有显著差别(PD分离架构下,P节点不需要存储 kv cache,D节点需要)
2. 解决方案
整体架构
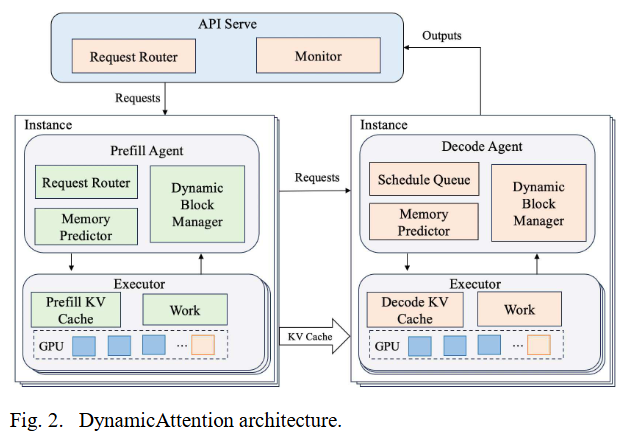
-
Prefill Agent 和 Decode Agent 都有:
-
Queue,管理请求队列,Request Router 和 Schedule Queue 都是一个 Queue
-
Memory Predictor,用来预测内存需求,然后调用 CUDA API 去分配显存
-
Dynamic block manager,应该是用来管理虚拟地址空间的
-
-
Executor:比较类似千帆的 ModelServer
-
KV Cache 就是 kv 缓存,类似我们的 AttentionStore
-
Work 就是推理引擎,负责 token 生成
-
核心思路:This paper proposes DynamicAttention, which addresses the aforementioned issues by allocating a continuous virtual memory space at startup without actually allocating physical memory
We have implemented DynamicAttention using over 4000 lines of Python code and 800 lines of Golang code
-
程序启动,先分配一块大的虚拟地址空间,完成 kv 的初始化
-
然后每次推理都预测下一个 step 的显存需求,按需分配和映射
2.1. 内存需求预测
有2种算法,分 prefill 和 decode
这2个算法都返回 WinSize,NeedResource
WinSize 表示内存需求的采样周期,The prediction algorithm runs at a fixed interval to forecast the next consumed GPU memory resources
NeedResource 表示需要的资源量


但是这里的疑问比较多
prefill 的疑问:
WinSize 应该是最长的 prompt 的执行时间, In the prefill phase, we select the longest request processing time among the current batch of prompts as the time window.
-
prefill 也是 batch 执行的,所以执行时间应该是所有请求的 prompt 一起的执行时间 the current batch of prompts,看单个 req 的 prompt 执行时间好像意义不大。除非请求的 token 数很少,不然 prefill 都是计算密集型的
decode 的疑问更多了:
We record the time it takes for each Prompt to generate a token and select the longest scheduling batch time as the time window
当前是 PD 分离架构
DecodeUsedTimeMap[req] 记录的是生成1个token的时间?还是整个请求的时间?
1. 如果是生成1个token的时间,那理论上每个请求在这里的时间都是一样的,因为是 batch 生成
2. 如果是一个请求的完整的decode时间。那下面的 StaticResource = BatchSize * TokenMemorySize 就对不上了(但是 prefill 是能对上的)。而且请求的输出不可预测,所以也没法算请求的所有Decode的时间。
结论(猜测):
WinSize 大概率就是每个 step 的时间(prefill 就是 batch prefill 耗时,decode 就是每一轮 decode 的耗时)
NeedResource 表示当前需要的静态资源,以及观测到的上一个状态的动态资源(MaxMemoryUsageList[t-1] – StaticResourceList[t-1]),显存使用的观测用的是 DCGM
2.2. 动态 kv 缓存管理
算法

疑问:
-
sequence.N 具体是指什么,论文没明确
大体思路,如果当前显存使用已经超过 ResourceThreshold,就释放掉某个请求的 kv cache,否则就继续分配 NeedResource
2.3. 虚拟显存
nvidia driver API 提供3个接口用来实现虚拟显存地址的管理
cuMemAddressReserve, cuMemCreate, and cuMemMap
具体用法可以参考:
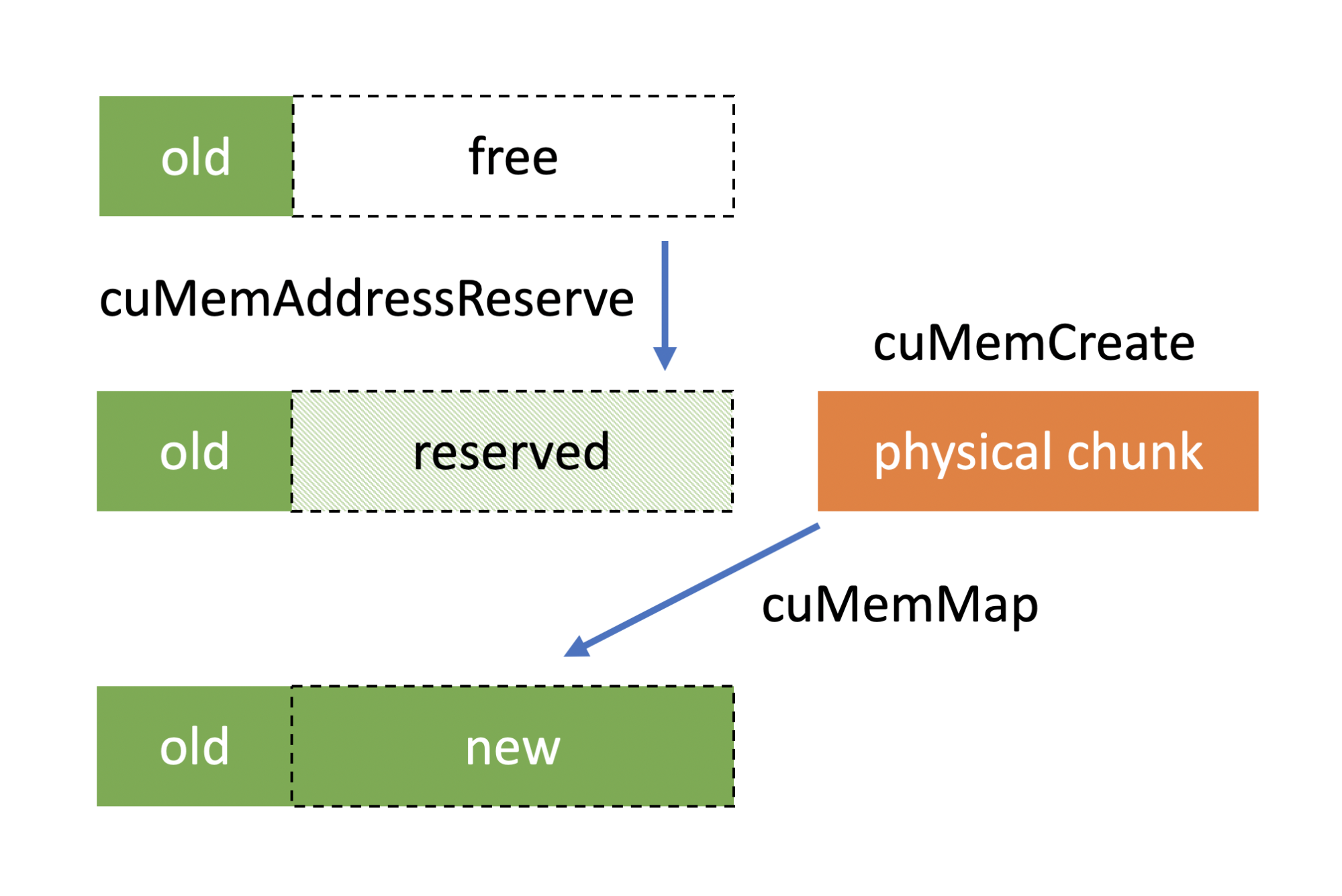
从目前论文了解的信息来看,只有 kv cache 用了这个技术,权重没有用
3. 性能测试
3.1. 测试场景
硬件:A100 x 4
数据集:ShareGPT,We choose 700 prompts of different input lengths to simulate different workloads, and require that the number of dialogue rounds be greater than two and there should be significant differences in input length
关键:
-
2轮对话
-
长度有显著差别
模型:LlaMa-2-13B,从数据推测,使用的是 fp16,权重占用 26GB
基准:DistServe,当前已开源的PD分离的SOTA实现
评估方法:看 prefill 和 decode 的平均延迟,p90分位延迟
3.2. 显存利用率
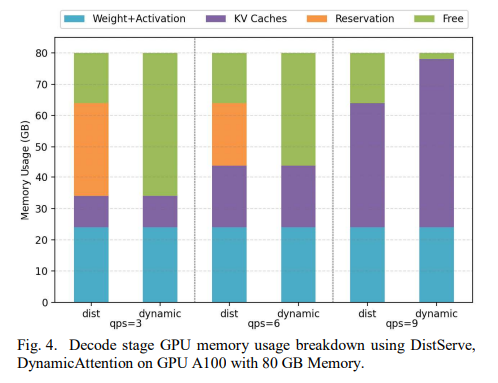
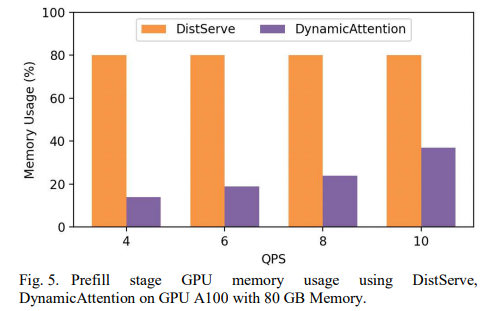
dist vs dynamic
核心优势:dist 启动时按 80% 占用启动引擎,当负载很低时,显存占用一直都是 80%,无法释放。但是如果使用 dynamic,这部分内存在低负载时是不占用的,可以给其他服务使用。
一些存疑的地方:
-
论文还提到对于高负载时,dynamic 可以把显存使用到 98.4% > 80%,这点感觉不太合理,因为引擎启动时的显存使用率 80% 只是个经验值,但是实际上你也可以配置 0.96,实际显存使用率可以达到 98%
-
PD 分离场景下,论文对比测试时,DistServe 仍然使用了 80% 的 –mem-fraction-static 参数启动,以此来体现 dynamic attention 的收益,但是实际上 P 节点可以把这个参数配置成 60%,因为 P 本身不需要保存太多 kv,bs 通常是1,token通常不超过4k,layerwise 传输
3.3. 延迟提升
这个 AegisServe 是啥?是 dyanmic 吗?
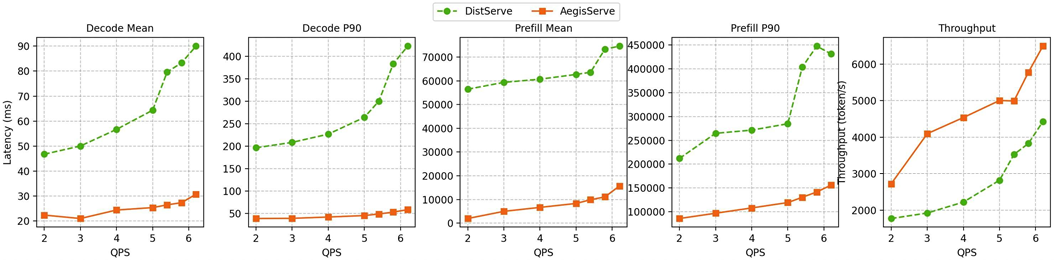
This demonstrates that through the optimization techniques such as latency recovery in DynamicAttention and prediction algorithms, we can effectively reduce the additional latency caused by memory allocation
require that the number of dialogue rounds be greater than two and there should be significant differences in input length