多头潜在注意力论文:
- deepseek-v2: https://arxiv.org/pdf/2405.04434
- deepseek-v3: https://arxiv.org/pdf/2412.19437
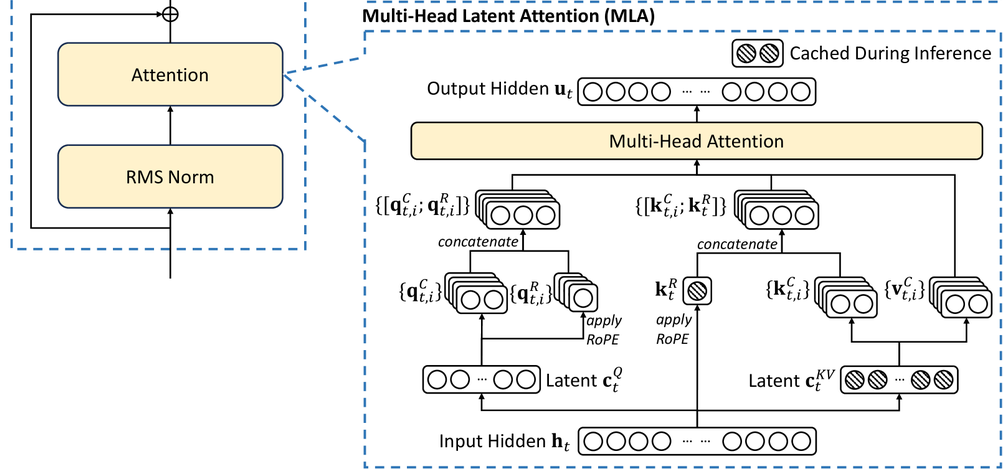
MLA 最核心的理念就是低秩转换
我们回顾一下最基本的 attention 计算,这里直接省略各种 MHA,MQA,GQA,因为这些 attention 变种并没有本质的改变了 attention 的计算公式,只是简单的共享
Q = W_q x\\ K = W_k x\\ V = W_v x\\ A=softmax(Q^TK / \sqrt{d}) \\ O = AV \\ Y = W_o O \\ MLP其中 x 是 [1, h] 矩阵,W_k 是 [h, h] 矩阵,因此,QKV 都是 [1, h] 矩阵,推理过程中的 KV 显存占用 sizeof(fp16) * 2 * b * l * h * s = 4bhls,即使使用最先进的 GQA,显存占用也是 4bhls / 8
有没有一种无损的方法,降低 KV 缓存服用,又不影响模型的效果?
deepseek-v3 探索出了一种新思路
1. W 权重矩阵的低秩转换
大模型推理过程中保存的是 KV,计算的 A,W_k也只在这2个地方会用到
W_k = W_{UK} W_{DK}其中 DK 表示 down-projection matrix 降维矩阵,UK 表示 up-projection matrix 升维矩阵
K = W_{UK} W_{DK} * x\\ A=softmax((W_q * x)^T * (W_{UK} W_{DK} * x) / \sqrt{d}) \\到这里就很关键了,虽然矩阵乘法不支持交换律,但是矩阵乘法还遵循一个定理(AB)^T = B^T A^T
因此有:
K = W_{UK} W_{DK} * x\\ A=softmax((x^T * W^T_q * (W_{UK} W_{DK} * x) / \sqrt{d}) \\如果只是简单的做 W_k的低秩转换,每次计算 A 的时候,K 还需要乘上一个 W_{UK},虽然节省了显存,但是增加了计算量,不是好事
亮点来了,这个计算 A 的时候,W_{UK}是可以被 W^T_q吸收掉的!
于是公式就变成了:
C^{KV} = W_{DK} * x \\ W^{new}_q = W^T_q * W_{UK} \\ A = softmax(x^T W^{new}_q C^{KV})实际上在作者的论文里面:
- KV 2个缓存直接合并成1个缓存 C^{KV}
- W_{UK}被吸收到W_q里面,W_{UV}被吸收到了W_o里面
- Q 也做了同样的低秩转换,节省了训练的内存
如下所示:


2. RoPE 解耦
但是现在有一个最大的问题就是,现在基本所有的大预言模型都会启用 RoPE,RoPE 本质是一个对角矩阵,目的是为了在计算 attention 的时候引入 token 之间的位置信息,这样能够更好的理解上下文和生成质量
Q,K 都需要应用 RoPE,V不需要
原始的 RoPE:
Q^T_mK_n = (R^d_{\Theta,m} W_q x_m)^T(R^d_{\Theta,n} W_k x_n) = x^T_m W^T_q R^d_{\Theta,n-m} W_k x_n低秩转换之后:
这就导致x^T * W^T_q * (W_{UK} W_{DK} * x)之间对会多一个 R^d_{\Theta,n-m}
x^T * W^T_q * R^d_{\Theta,n-m} * (W_{UK} W_{DK} * x)这样W_{UK}就没法简单的被W^T_q吸收了,因为矩阵运算不支持交换律,如果没法吸收,那就必须在推理的时候,增加一次计算,这样又不划算了
对于这个问题,目前唯一可借鉴的方法,就是放弃 RoPE,使用其他位置编码算法如ALIBI,但 DeepSeek 的实验显示其他现有方法的效果都不太行
最后论文使用了一个折中的算法:Q、K新增d_r个维度用来保存RoPE信息,计算 Attention 的时候,计算 Attention 的时候,矩阵拼接就直接变成加法了
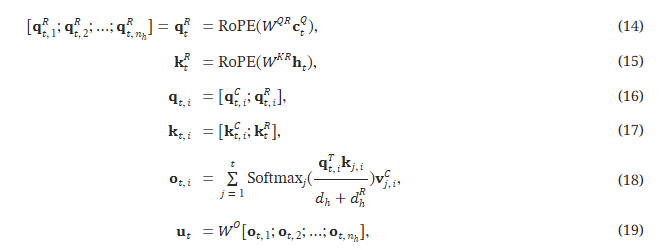
相当于原有的 Q^TK加上 q^R_t k^R_t,再做 softmax,这样 Q^TK可以继续使用之前的 MLA 算法
疑问:
- 能想到这个方法,并且效果不失真,怎么找到的?
3. 推理的性能提升
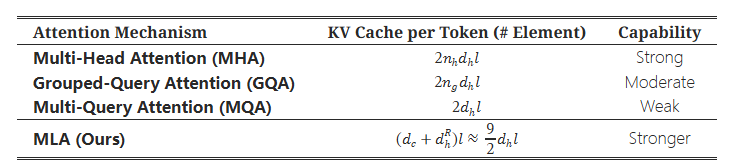
参考 https://huggingface.co/deepseek-ai/DeepSeek-V3/blob/main/config.json 的数据
d_c = 512 对应配置 kv_lora_rank
d^R_h = 64 对应配置 qk_rope_head_dim
性能提升:
-
对比 MHA:kv 大小相当于从 MHA 的 128 * 128 = 16384 优化到了 512 + 64 = 576,显存降低 2*16384/57=56 倍,相当于bs提升56倍
-
对比 GQA = 8:也相当于bs提升了 2 * 8 * 128 / 576 = 3.6 倍
-
对比 GQA = 16:由于这个模型更大,同等参数量,GQA可能得是 g = 16 才能保证效果?bs提升 7.2 倍
4. 模型配置
self_attn 相关的权重文件:https://huggingface.co/deepseek-ai/DeepSeek-V3/raw/main/model.safetensors.index.json
weight_scale_inv 文件先不管(不知道是干啥的,但应该不关键)
"model.layers.52.self_attn.q_a_proj.weight": "model-00136-of-000163.safetensors",
"model.layers.52.self_attn.q_a_layernorm.weight": "model-00136-of-000163.safetensors",
"model.layers.52.self_attn.q_b_proj.weight": "model-00136-of-000163.safetensors",
"model.layers.52.self_attn.kv_a_proj_with_mqa.weight": "model-00136-of-000163.safetensors",
"model.layers.52.self_attn.kv_a_layernorm.weight": "model-00136-of-000163.safetensors",
"model.layers.52.self_attn.kv_b_proj.weight": "model-00136-of-000163.safetensors",
"model.layers.52.self_attn.o_proj.weight": "model-00136-of-000163.safetensors",
"model.layers.52.self_attn.o_proj.weight_scale_inv": "model-00136-of-000163.safetensors",
对应的 mapping 代码:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/convert.py
mapping = {
"embed_tokens": ("embed", 0),
"input_layernorm": ("attn_norm", None),
"post_attention_layernorm": ("ffn_norm", None),
"q_proj": ("wq", 0),
"q_a_proj": ("wq_a", None),
"q_a_layernorm": ("q_norm", None),
"q_b_proj": ("wq_b", 0),
"kv_a_proj_with_mqa": ("wkv_a", None),
"kv_a_layernorm": ("kv_norm", None),
"kv_b_proj": ("wkv_b", 0),
"o_proj": ("wo", 1),
"gate": ("gate", None),
"gate_proj": ("w1", 0),
"down_proj": ("w2", 1),
"up_proj": ("w3", 0),
"norm": ("norm", None),
"lm_head": ("head", 0),
"scale": ("scale", None),
}
再结合 MLA 的代码:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/model.py
class MLA(nn.Module):
def __init__(self, args: ModelArgs):
// ...
if self.q_lora_rank == 0:
self.wq = ColumnParallelLinear(self.dim, self.n_heads * self.qk_head_dim)
else:
self.wq_a = Linear(self.dim, self.q_lora_rank)
self.q_norm = RMSNorm(self.q_lora_rank)
self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim)
self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim)
self.kv_norm = RMSNorm(self.kv_lora_rank)
self.wkv_b = ColumnParallelLinear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim))
self.wo = RowParallelLinear(self.n_heads * self.v_head_dim, self.dim)
// ...
5. sglang 源码实现
deepseek 的模型的attention和传统的模型不一样,attention的权重矩阵形状是 [dim数量, dim的hidden_size],dim数量=head数量 * 每个head的dim数量,所以一般权重矩阵也可以表示为 [head数量,每个head的dim数量,dim的hidden_size]
传统的模型,dim数量和hidden_size绝大部分都是一样的,比如7b模型,都是4096,70b模型就是8096
deepseek模型的hidden_size是 7168

但是dim数量是 128 * 128 = 16384

deepseek 模型核心的权重文件其实就4个:
- self_attn.kv_a_proj_with_mqa -> 对应论文的 W^{DKV} + W^{KR},矩阵大小是 [576, 7168],这个 576 是 kv_lora_rank(512) + qk_rope_head_dim(64)
- self_attn.kv_b_proj.weight -> 对应论文的W^{UK}和 W^{UV},deepseek 是把这2个放大权重放在一个 tensor 里了,权重加载完之后需要 split 一下,代码里有。矩阵的大小是 [32768, 512],所以单个 W^{UK}是 [16384, 512],其中 16384 就是 dim数量 = 128 * 128,所以 W^{UK}也可以写成 [128, 128, 512]
- self_attn.o_proj -> 对应论文的 xx,矩阵大小是 [7168, 16384]
- self_attn.q_a_proj.weight -> 对应论文的W^{DQ},矩阵大小是 [1536, 7168]
- self_attn.q_b_proj.weight -> 对应论文的W^{UQ + QR},矩阵大小是 [24576, 1536],刚好W^{UQ}是[128, 128, 1536],W^{QR}是[128, 64, 1536]
再简单梳理一下:
- W^{DKV}:KV的低秩转换矩阵,矩阵形状 [512, 7168]
- W^{KR}:K的RoPE权重矩阵,矩阵形状 [64, 7168]
- W^{UK}:K的放大矩阵,矩阵形状 [128, 128, 512]
- W^{UV}:V的放大矩阵,矩阵形状 [128, 128, 512]
- W^{DQ}:Q的低秩转换矩阵,矩阵形状 [1536, 7168]
- W^{UQ}:Q的放大矩阵,矩阵形状是 [128, 128, 1536]
- W^{QR}:Q的RoPE权重矩阵,矩阵形状是 [128, 64, 1536]
至此,论文中所有涉及到的关键权重参数都清晰了
5.1. 权重加载
DeepseekV2ForCausalLM 的 load_weights 函数
代码使用了 python 的 for break 语法糖,看着比较别扭,简单来说其实就是,先加载 专家权重,再加载共享专家,再加载 attention 权重
加载完权重,最后有一个处理
954 w_kc, w_vc = w.unflatten( 955 0, (-1, self_attn.qk_nope_head_dim + self_attn.v_head_dim) 956 ).split([self_attn.qk_nope_head_dim, self_attn.v_head_dim], dim=1) 957 self_attn.w_kc = w_kc.transpose(1, 2).contiguous().transpose(1, 2) 958 self_attn.w_vc = w_vc.contiguous().transpose(1, 2)
这里就是把 kv_b_proj 切成原来的W^{UK}和 W^{UV},所以这里 w_kc 是 k的放大权重,w_vc 是 v的放大权重
5.2. 推理
MLA的推理有2个实现,我们只需要关心 forward_absorb 即可
以 tp=8 为例
1)计算 Q
输入:hidden_states,形状是 [7168, 1]
if self.q_lora_rank is not None:
q = self.q_a_proj(hidden_states)[0]
q = self.q_a_layernorm(q)
q = self.q_b_proj(q)[0].view(-1, self.num_local_heads, self.qk_head_dim)
else:
// ...
q_nope, q_pe = q.split([self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_a_proj(x) 得到压缩后的 q [1, 1536],W^{DK} [1536, 7168] * x[7168, 1] = q[1, 1536]
q_a_layernorm 不改变矩阵形状,先忽略
q_b_proj(x) 放大,得到未压缩的 q,q[1, 1536] * W^{UQ+QR}[1536, 24576] = q[1, 128, 192],如果tp=8,得到的就是 q[1, 16, 192]最后沿着dim=-1最后一个维度,把 pe 信息切开,得到
q_nope[1, 16, 128] 和 q_pe[1, 16, 64]
q_nope_out = torch.bmm(q_nope.transpose(0, 1), self.w_kc)
q_input[..., : self.kv_lora_rank] = q_nope_out.transpose(0, 1)
这一步其实就是把W^{UK}吸收到 q_nope 里面去,W^{UK}是 [128, 128, 512],tp=8的话就是 [16, 128, 512]
所以:
q_nope[16, 1, 128] * w_kc [16, 128, 512] = q_nope_out[16, 1, 512] // 注意这里的 q_nope把第一维和第二维做了一个转置操作,矩阵才能计算。
这样就得到了 q 和 q_pe
q_input 由于拼接了 q 和 q_pe,所以他的形状就是 [16, 1, 576]
2)计算 KV
接着计算 kv,这个就更简单了,kv用的就是压缩后的kv
latent_cache = self.kv_a_proj_with_mqa(hidden_states)[0]
v_input = latent_cache[..., : self.kv_lora_rank]
v_input = self.kv_a_layernorm(v_input.contiguous()).unsqueeze(1)
k_input = latent_cache.unsqueeze(1)
k_input[..., : self.kv_lora_rank] = v_input
k_pe = k_input[..., self.kv_lora_rank :]
q_pe, k_pe = self.rotary_emb(positions, q_pe, k_pe)
q_input[..., self.kv_lora_rank :] = q_pe
k_input[..., self.kv_lora_rank :] = k_pe
latent_cache = kv_a_proj_with_mqa[576, 7168] * x[7168, 1] = [576, 1],这个 576 是 kv_lora_rank(512) + qk_rope_head_dim(64)
positions 信息经过 q_pe 和 k_pe 计算之后,直接赋值到 q_input 和 k_input 里面
至此
q_input [1, 16, 576]
k_input [1, 1, 576]
v_input [1, 1, 512] // v 不需要有 pe 信息,所以少了 64
3)计算 attn * V
attn_output 的形状就是 [1, 16, 512],576在qk转置的计算中已经消掉了
attn_output = self.attn_mqa(q_input, k_input, v_input, forward_batch)
attn_output = attn_output.view(-1, self.num_local_heads, self.kv_lora_rank)
接着
attn_bmm_output = torch.bmm(attn_output.transpose(0, 1), self.w_vc)
attn_output = attn_bmm_output.transpose(0, 1).flatten(1, 2)
w_vc 就是 v 的放大矩阵,形状是 [16, 128, 512],为了方便计算,权重加载的时候把 v 做了 transpose(1, 2),所以他的形状其实是 [16, 512, 128]
那 attn_output[16, 1, 512] * w_vc[16, 512, 128] = attn_bmm_output[16, 1, 128]
attn_bmm_output.transpose(0, 1) 就是 [1, 16, 128]
flatten(1, 2) 是合并维度操作,合并第1和第2维度(维度从0开始的),16*128=2048,最后就是 [1, 2048]
4)计算 O
o_proj 形状是 [7168, 16384],tp=8的时候就是 [7168, 2048]所以 o_proj(attn) 之后的向量就是 [7168, 1],继续输入给下一层的 transformer block
6. tp 并行
看知乎上大家的讨论,MLA在支持TP并行的时候,由于kv head只有1个,所以kv在不同的GPU上是完全拷贝的
我看了下sglang的实现,Q是支持TP并行的,KV确实是每个TP都拷贝了一份
个中理由,暂时还没理解