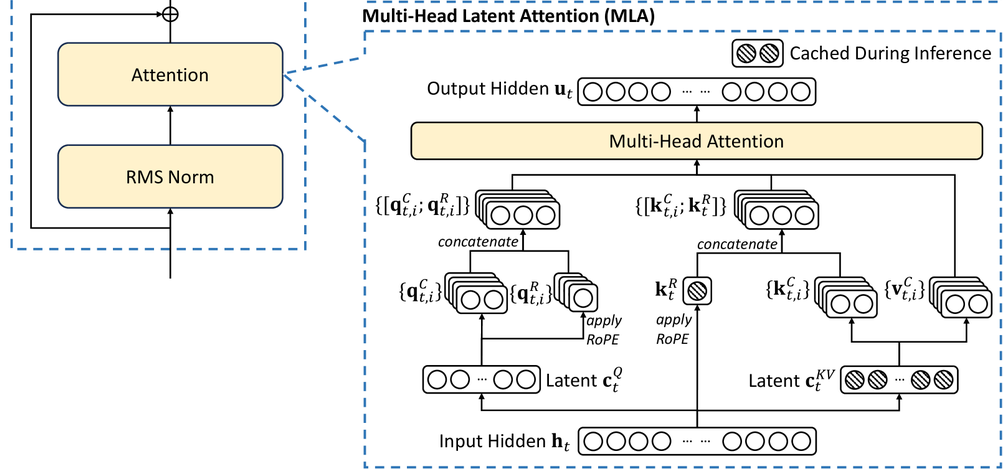
多头潜在注意力论文:
- deepseek-v2: https://arxiv.org/pdf/2405.04434
- deepseek-v3: https://arxiv.org/pdf/2412.19437
MLA 最核心的理念就是低秩转换
我们回顾一下最基本的 attention 计算,这里直接省略各种 MHA,MQA,GQA,因为这些 attention 变种并没有本质的改变了 attention 的计算公式,只是简单的共享
Q = W_q x\\ K = W_k x\\ V = W_v x\\ A=softmax(Q^TK / \sqrt{d}) \\ O = AV \\ Y = W_o O \\ MLP其中 x 是 [1, h] 矩阵,W_k 是 [h, h] 矩阵,因此,QKV 都是 [1, h] 矩阵,推理过程中的 KV 显存占用 sizeof(fp16) * 2 * b * l * h * s = 4bhls,即使使用最先进的 GQA,显存占用也是 4bhls / 8
有没有一种无损的方法,降低 KV 缓存服用,又不影响模型的效果?
deepseek-v3 探索出了一种新思路