最近 openai 发布圣诞系列的第一弹,就强调了强化微调,基于这个,可以让小模型结合行业数据,做到比大模型更强的推理效果
然后研究了下字节之前发过的类似的一篇论文:https://arxiv.org/pdf/2401.08967
1. 背景
1.1. 传统的 CoT 训练方法
虚线之上是传统的 CoT 训练方法,就是使用数据集(x, e, y)不断的训练基础模型,让基础模型获得推理能力
比如 gsm8k 数据集:https://huggingface.co/datasets/openai/gsm8k/viewer/main/train?p=1&row=167
这个数据集里面每一行就是一条训练数据,包括3部分:
x就是问题
e就是解决这个问题的思路
y是答案
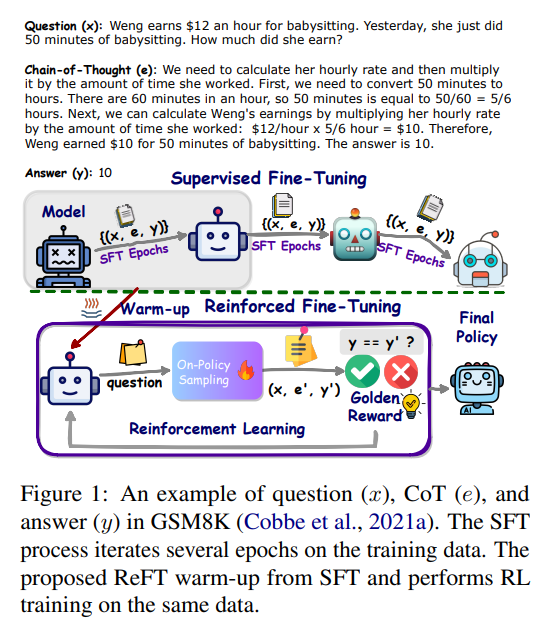
但是这种训练方法,模型推理的泛华能力是比较弱的,因为它只能学习到一种解题思路,就是数据集中的思路
1.2. ReFT:Reinforced Fine-Tuning
训练思路和 SFT 很不一样同一条数据集,SFT 会反复训练多次,让模型在数据集上误差最小。这样训练出来的模型,对于解决数据集中的问题肯定是没问题的,但是对于解决数据集的其他问题,就不一定是最佳的了。这个时候回答问题的质量取决于数据集的质量和规模ReFT 只需要1~2次预热,得到一个基础的模型,然后通过强化学习,让模型主动去探索不同的解题路径,这样得到的模型,泛化能力是最强的
如上图,ReFT 有2个核心阶段:
- warm-up:xx
- 强化学习阶段:specifically Proximal Policy Optimization (PPO)
特别注意:ReFT 并不依赖额外的训练数据集通过这个方法,论文使 CodeLLAMA 和 Galactica 模型在GSM8K、MathQA、SVAMP数据集上,泛化能力得到了显著提高