论文:2个版本论文不太一样
- v1 https://arxiv.org/pdf/2310.08560v1
- v2 https://yiyibooks.cn/arxiv/2310.08560v2/index.html
代码:https://github.com/cpacker/MemGPT
核心亮点:
- 在有限的上下文窗口(8k)里,支持无线上下文的“错觉”,属于长文的一种解决方案
- 对智能体友好,能够提供超长记忆力,以及个性化的智能体体验
1. 产品场景
微软的类似产品能力:https://microsoft.github.io/autogen/docs/ecosystem/mem0
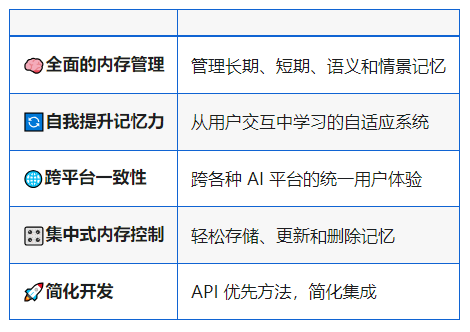
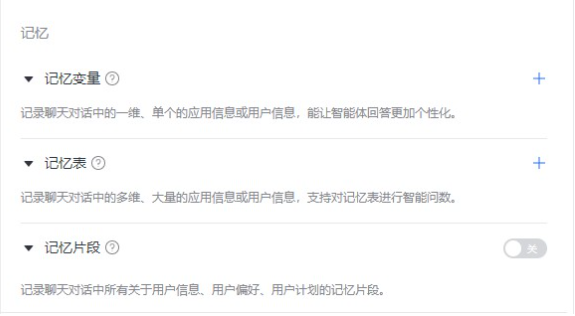
千帆 app-builder 类似的产品能力:
2. 论文背景
由于 Transformer 架构的自注意力机制,直接扩展 Transformer 的上下文长度会导致计算时间和内存成本成倍增加,这使得新的长上下文架构的设计成为紧迫的研究挑战(戴等人,2019; Kitaev 等人, 2020; Beltagy 等人, 2020)。虽然开发更长的模型是一个活跃的研究领域(Dong等人,2023),即使我们能够克服上下文缩放的计算挑战,最近的研究表明长上下文模型很难利用额外的上下文实际上(Liu等人,2023a)。因此,考虑到训练最先进的大语言模型所需的大量资源以及上下文扩展的收益递减,迫切需要替代技术来支持长上下文。
在本文中,我们研究如何在继续使用固定上下文模型的同时提供无限上下文的错觉。我们的方法借鉴了虚拟内存分页的理念,该理念通过在主内存和磁盘之间进行数据分页,使应用程序能够处理远远超出可用内存的数据集。
在MemGPT中,我们将上下文窗口视为受限内存资源,并为大语言模型设计了类似于传统操作系统中使用的内存层的内存层次结构(Patterson等人,1988)。传统操作系统中的应用程序与虚拟内存交互,通过将溢出数据分页到磁盘,并在应用程序访问时(通过页面错误)将数据检索回内存,提供了一种内存资源多于物理内存(即主内存)实际可用资源的假象。为了提供更长上下文长度(类似于虚拟内存)的类似错觉,我们允许大语言模型通过 “大语言模型操作系统”(我们称之为 MemGPT)来管理放置在自己上下文中的内容(类似于物理内存)。MemGPT 使大语言模型能够检索上下文中丢失的相关历史数据,并且还可以将不太相关的数据从上下文中驱逐到外部存储系统中。图3说明了MemGPT的组件。
