一、摘要
MoonCake设计了KV Cache分离式架构,该架构下prefill和decode分离为2个集群。同时,存算分离KV Cache利用了GPU集群的CPU、MEM、SSD资源来构建。
1、MoonCake关键核心:以KV Cache为中心的调度,该调度核心价值:最大化吞吐、同时不打破TTFT和TBT。
2、MoonCake应对超高负载:设计了提前预估的拒绝策略
3、MoonCake效果:模拟场景中,MoonCake相比基线提升了5倍多的吞吐(满足延迟前提下)
4、MoonCake实际应用:MoonCake使得Kimi处理的请求量提升了75%
二、结论
为了高效LLM推理,尤其是在长上下文和超载场景,我们设计了MoonCake。文章中讨论了该架构的必要性、挑战、针对最大化吞吐和保障延迟间做的设计折中。
三、介绍
1、研发分离式KV Cache背景和动机
-
prefill和decode具有不同计算特性,prefill偏计算,decode偏显存和带宽,拆分有利于提升资源利用率和吞吐
-
最大化吞吐的核心办法:prefill阶段最大程度reuse KV Cache(本地Cache+远程Cache)、推理阶段在一个batch中最大化token数量(提升MFU,模型浮点计算)
-
核心问题:最大化吞吐,通过远程Cache复用会增大TTFT,增大batch的size过大会导致TBT变大
-
关键解法:设计一个分布式KV Cache,并以他为中心设计核心调度和优化
2、关键流程
-
关键核心流程设计:对于一个请求,全局调度器Conductor根据最大化Cache和工作负载相结合原则,挑选prefill实例及decode实例
-
1)传输尽可能多的可复用KV Cache到被选择的prefill实例
-
2)按层分块并行完成prefill stage,并且prefill stage过程中按层分块流式传输KV Cache到对应decode实例
-
3)decode实例load 被写入本地的KV Cache,然后继续流程完成推理
-
3、核心挑战
-
prefill阶段(最大化复用KV Cache)
-
内存/SSD KV Cache load时延保证:分布式KV Cache核心存储在内存和SSD,如何控制加载时间,不影响TTFT
-
短时间高并发大量KV Cache传输时延保证:存在KV Cache需要远程传输到本地,可能会出现网络拥塞,进一步加剧延迟
-
调度优化和保障:Conductor需要预测未来KV Cache的使用情况,并提前执行swap或多副本策略
-
-
最热的一些block Cache,需要复制到多个节点,避免网络拥塞
-
-
-
内存限制:单机内存大部分被KV Cache Pool预留,留给prefill调度的内存有限,影响调度效果?
-
-
decode阶段(最大化增加batch size,增加token数量)
-
batch过大,TBT SLO可能被打破
-
prefill实例节点显存有限,影响size数量
-
-
负载调度
-
请求提前拒绝:prefill后,需要预测是否有decode槽位(空闲decode实例),如果没有则需要尽早拒绝,节省资源给其他请求
-
粗暴拒绝会导致负载波动剧烈:需要预估生成的长度,然后做短期内的全局的负载预估,支撑更好的拒绝策略
-
优先差异调度:区分不同请求优先级,实现更好的优先级调度
-
4、关键策略设计
-
CPP:Chunk Pipline Parallelism,将一个请求跨多节点并行处理,并且优化了网络占用,以应对长文本分布的动态变化,这样可以有效降低TTFT
-
中心式KV Cache请求调度算法:基于启发式的自动化热点迁移方案,自动复制热的KV Cache块,无需依赖 精确预估未来KV Cache使用。能显著降低TTFT
-
请求拒绝:基于实例系统负载,决定是接受请求还是拒绝请求
四、相关工作
五、核心设计
5.1 整体架构
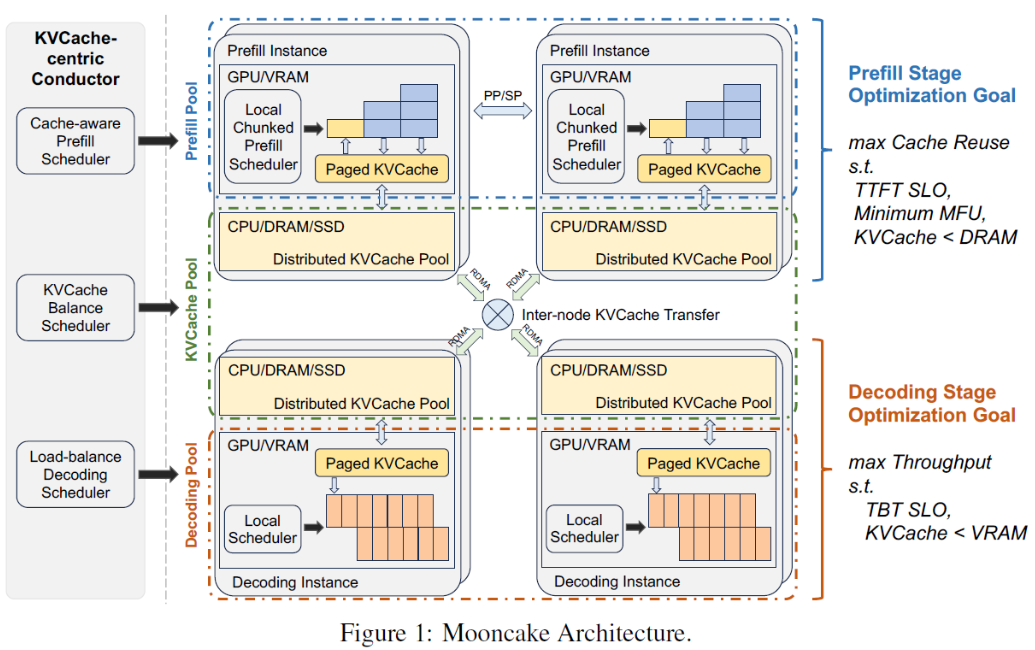
1、Conductor:根据当前KV Cache分布和实例负载,选择合适的prefill和推理实例(一次性计算到位,具体推理时候做二次计算校验)用于调度
2、请求处理的核心流程
-
-
KV Cache Reuse:被选中的prefill实例,受到的请求包含:原始请求输入、能够被复用的cache(命中prefix cache)的KV Block ID列表和这个请求被分配的所有用来存Cache的Block ID列表。并需要从远程节点读取KV Cache到本地的Memory,然后到HBM
-
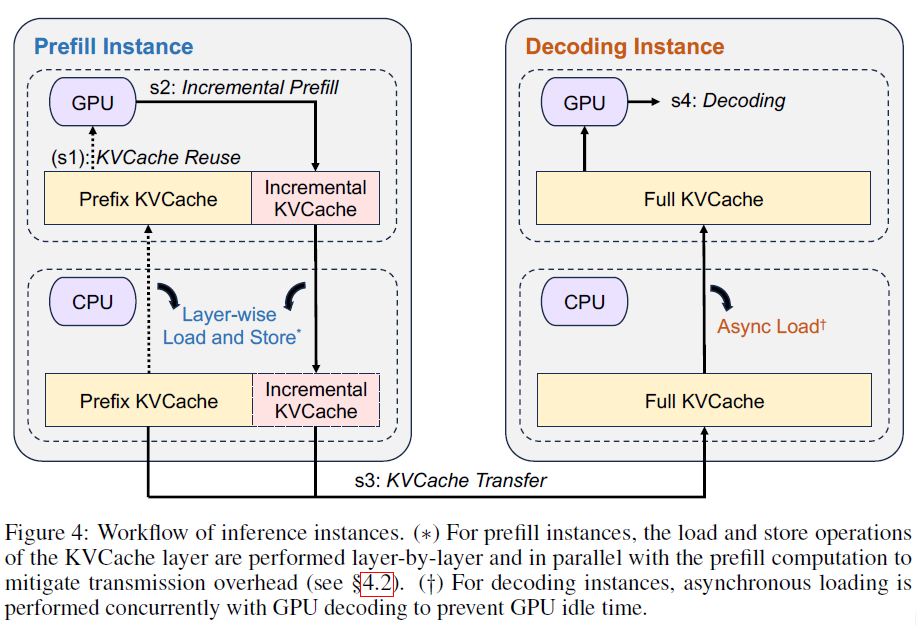
Incremental Prefill:被选中的prefill实例,利用HBM中的KV Cache完成prefill,并将新的token的KV Cache写入Memory。如果没有命中Cache的token数量超过一定阈值(如1k个token),则prefill会被拆成多个小的prefill,在多个prefill实例上并行完成prefill计算
-
KV Cache Trans:单机部署一个Messenger独立进程服务,用来管理和传输Cache。当Messenger收到信号后,就会触发高速、跨机KV Cache传输。这个过程与Incremental Prefill完全并行且异步执行,并且是按层-Chunk粒度流式传输
-
Decoding:prefill实例所有KV Cache传输到decode实例后,该请求加入decode的下一个批次处理。因为该decode实例是Conductor最初预选的,真实进入decoe阶段后,decode实例上的local Scheduler会做二次判断,推理耗时(预估推理长度)是否会打破TBT SLO。如果有打破风险,则拒绝请求,同时该请求之前的prefill就会浪费掉
-
3、分布式KV Cache
-
-
存储位置:存储在GPU实例的CPU Memory中(后续可以结合AttentionStore,利用SSD)
-
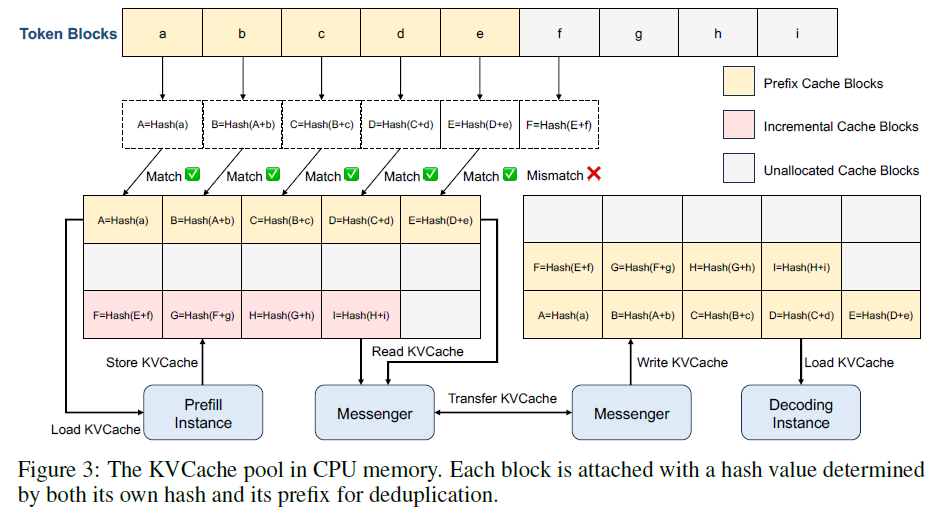
存储格式:按照PagedCache方式,分Block存储,每个Blcok关联了一个Hash值,Hash值=Hash(Block + Block_pre)。Hash值可以快速计算命中的最大Cache
-
缓存管理:可以使用LRU等算法,做缓存换入换出、淘汰等
-
4、KV Cache传输
-
-
传输路径:CPU Memory –>RDMA –> CPU_Memory
-
访问边界:Messenger负责prefill阶段KV Cache读取、KV Cache传输、decode KV Cache写入
-
六、具体实现
6.1 PrefillPoll实现
MultiNode-Prefill:
-
核心思想:将prefill pool分成N个组,每组X台机器,X台机器组成一个流水线,并行处理N个请求,一台机器同时处理多个请求的不同chunk阶段。一个请求的一个chunk处理完给下一台机器(需要传输KV Cache到下一台机器,用于该请求的下一个turnk计算),同时该机器处理新的请求的一个chunk
-
核心价值场景:应对请求上下文长度剧烈波动或不确定场景,出现热点或负载不均
Layerwise-Prefill:
-
核心思想:逐层prefill,通过launch和wait来完成关键预填充。
-
wait:每一层prefill(注意力)计算之前,通过wait等待该层所需的所有历史token KV Cache异步(从分布式KV Cache内存)加载到HBM完成,完成后开始计算
-
launch:每一层的prefill(注意力)计算完成后,会产生新的KV Cache,通过launch触发 新的KV写入KV Cache内存
-
所有层计算完成后,进程等待所有KV写入KV Cache内存完成
-
6.2 KV Cache调度
Prefill 全局调度:
-
核心思想:请求调度同时参考:实例负载、prefix cache命中长度、可复用KV Cache 块的分布(?)
-
核心实现:计算prefilltime + 实例负载导致的排队时间,两个因素同时纳入全局调度算法
-
核心流程:
-
对一个请求,拆分为多个block,为每个block计算hash key(后面的block(里面的所有token)计算hash时候需要带上前面blcok的hash)
-
对这个请求的所有blcok,与prefill pool中对应分组的所有prefill实例上的KV Cache计算prefix cache match length(prefix_len,这个逻辑vllm中单机的已经实现,没有实现跨机)
-
Conductor根据请求长度及Cache命中长度prefix_len(每个实例不同),预估prefill执行时间,再加上实例上的预估请求等待时间,得到TTFT,根据TTFT时间为实例打分。Conudctor最后选择TTFT最小的实例来处理该请求,并更新该实例Cache和排队时候。如果最小的TTFT都打破了SLO,则直接拒绝该请求
-
-
核心难点:
-
prefill 耗时预估:根据离线数据,开发了一个预估模型(根据请求长度及cache hit 长度),Transformer范式下,模型效果比较好
-
请求等待耗时预估:根据某个机器聚合所有排队过的历史请求的prefilltime来预估
-
传输时间预估:不仅是数据量大小决定,还取决于当前网络状态,尤其是传输数据的节点是否有网络拥塞情况
-
Cache 负载均衡:
-
核心问题:cache类型不同,访问频率存在很大差异。比如system prompt的cache基本被每个请求访问,而一个长文本的cache基本只背这一个用户访问
-
核心职责:制定backup cache策略,确保全局调度能使得在高cache命中率和低负载间平衡
-
核心解法:
-
制定Cache使用模型预估未来使用:收集每个Block Cache的的全局使用(访问)情况,然后使用模型预估未来使用,然后做相应决策(避免访问热点)
-
Cache使用预估难点:workloads(用户输入)是动态变化和不确定的,并且有可能随着时间变化剧烈
-
Cache使用预估效果保障:设计一个启发式的自动热点迁移机制,以增强cache负载均衡
-
-
-
核心策略:一个请求不会总是发给Cache命中最大的prefill实例,因为可能该实例负载很高
-
次优选实例选择策略:预估次优选实例未命中Cache部分的额外部分(相比最长Cache实例)prefill时间<传输时间,则直接将最长Cache实例位置和请求发给次优实例
-
重新计算还是传输策略:当最优实例的Cache命中长度< 次优实例的缓存长度 * 阈值(>1,阈值需要根据实际情况摸索)时候,则倾向直接在次优实例计算没有Cache的部分,而不是等待Cache传输(实现prefill时间最优)
-
缓存复制策略(prefill实例之间):次优实例主动从最长Cache实例同步差异的KV Cache到本地(实现热点缓存自动扩散分布)
-