一、摘要
MoonCake设计了KV Cache分离式架构,该架构下prefill和decode分离为2个集群。同时,存算分离KV Cache利用了GPU集群的CPU、MEM、SSD资源来构建。
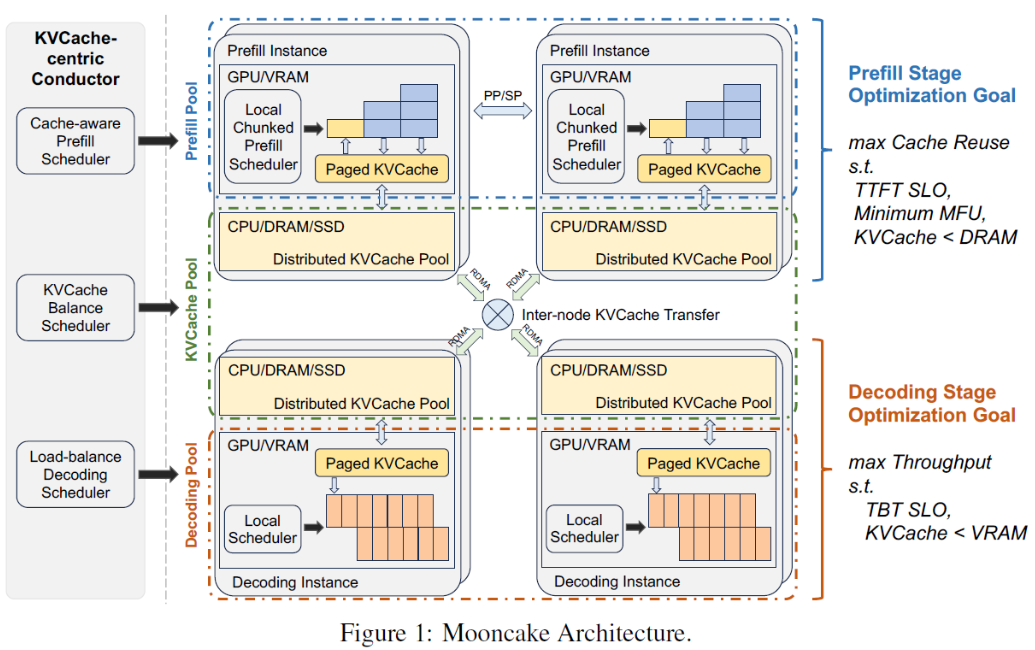
1、MoonCake关键核心:以KV Cache为中心的调度,该调度核心价值:最大化吞吐、同时不打破TTFT和TBT。
2、MoonCake应对超高负载:设计了提前预估的拒绝策略
3、MoonCake效果:模拟场景中,MoonCake相比基线提升了5倍多的吞吐(满足延迟前提下)
4、MoonCake实际应用:MoonCake使得Kimi处理的请求量提升了75%
二、结论
为了高效LLM推理,尤其是在长上下文和超载场景,我们设计了MoonCake。文章中讨论了该架构的必要性、挑战、针对最大化吞吐和保障延迟间做的设计折中。
三、介绍
1、研发分离式KV Cache背景和动机
-
prefill和decode具有不同计算特性,prefill偏计算,decode偏显存和带宽,拆分有利于提升资源利用率和吞吐
-
最大化吞吐的核心办法:prefill阶段最大程度reuse KV Cache(本地Cache+远程Cache)、推理阶段在一个batch中最大化token数量(提升MFU,模型浮点计算)
-
核心问题:最大化吞吐,通过远程Cache复用会增大TTFT,增大batch的size过大会导致TBT变大
-
关键解法:设计一个分布式KV Cache,并以他为中心设计核心调度和优化
2、关键流程
-
关键核心流程设计:对于一个请求,全局调度器Conductor根据最大化Cache和工作负载相结合原则,挑选prefill实例及decode实例
-
1)传输尽可能多的可复用KV Cache到被选择的prefill实例
-
2)按层分块并行完成prefill stage,并且prefill stage过程中按层分块流式传输KV Cache到对应decode实例
-
3)decode实例load 被写入本地的KV Cache,然后继续流程完成推理
-
3、核心挑战
-
prefill阶段(最大化复用KV Cache)
-
内存/SSD KV Cache load时延保证:分布式KV Cache核心存储在内存和SSD,如何控制加载时间,不影响TTFT
-
短时间高并发大量KV Cache传输时延保证:存在KV Cache需要远程传输到本地,可能会出现网络拥塞,进一步加剧延迟
-
调度优化和保障:Conductor需要预测未来KV Cache的使用情况,并提前执行swap或多副本策略
-
-
最热的一些block Cache,需要复制到多个节点,避免网络拥塞
-
-
-
内存限制:单机内存大部分被KV Cache Pool预留,留给prefill调度的内存有限,影响调度效果?
-
-
decode阶段(最大化增加batch size,增加token数量)
-
batch过大,TBT SLO可能被打破
-
prefill实例节点显存有限,影响size数量
-
-
负载调度
-
请求提前拒绝:prefill后,需要预测是否有decode槽位(空闲decode实例),如果没有则需要尽早拒绝,节省资源给其他请求
-
粗暴拒绝会导致负载波动剧烈:需要预估生成的长度,然后做短期内的全局的负载预估,支撑更好的拒绝策略
-
优先差异调度:区分不同请求优先级,实现更好的优先级调度
-
4、关键策略设计
-
CPP:Chunk Pipline Parallelism,将一个请求跨多节点并行处理,并且优化了网络占用,以应对长文本分布的动态变化,这样可以有效降低TTFT
-
中心式KV Cache请求调度算法:基于启发式的自动化热点迁移方案,自动复制热的KV Cache块,无需依赖 精确预估未来KV Cache使用。能显著降低TTFT
-
请求拒绝:基于实例系统负载,决定是接受请求还是拒绝请求
四、相关工作
五、核心设计
5.1 整体架构