https://arxiv.org/pdf/2311.18677
https://yiyibooks.cn/arxiv/2311.18677v2/index.html
论文的核心思想:不管是 Ocra、还是 ExeGPT、还是 SplitWise,论文都提到一些关键的特点,整个推理可以分为2部分,提示阶段(首token计算阶段)和词生成,这2个阶段的负载类型是截然不同的,对算力的要求也不一样,因此,通过拆分这2阶段的计算,未来资源池里面,一部分机器用来跑首 token 计算,一部分机器用来跑词生成,通过这个方式,整个推理的吞吐提升了2倍左右
1. 论文的一些洞察
1.1. 【关键】提示阶段和词生成阶段的token分布

由于编码服务的常见情况只需要在用户键入时在程序中生成接下来的几个单词,因此输出词符的中位数为 13 个标记。另一方面,对话服务几乎呈双峰分布,生成的 Token 中位数为 129 个。洞察1:不同的推理服务可能具有截然不同的token数量分布(提示阶段、词生成阶段)
1.2. 【关键】批处理利用率
batch size = 30,但不代表每时每刻都有 30 个请求在处理,实际情况有很多管道气泡 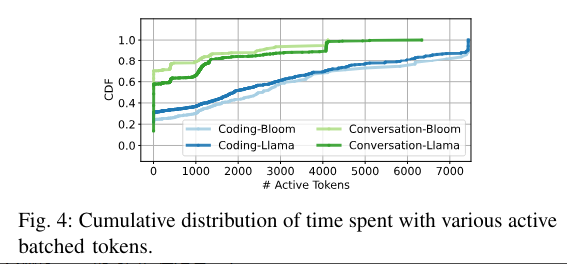
如果一个请求,在做词生成,那标记为1个活跃的token。上面这个图就是 GPU 活跃 token 数量的一个累计分布函数从这个图可以看出:
- 对 chat 来说:GPU 大概有 60% 的时间,在处理 < 20 的 token。
- 对于 code 来说:这个情况更差,大概有 30% 的时间,在处理 1 个 token
也就是说,GPU 实际运行过程中,是有非常多管道气泡的。比如 batch size 是 30,但是还是有很多时间,只有1个token在处理
推测:
Q:为什么会出现这个问题?
A:由于请求和 seq 长度存在一定的分布,所以必然会存在很多时刻,很多流水线是处于 “短暂” 的空闲的,这种空闲的时间片,就是管道气泡
Q:能不能通过缩小 Batch size 来降低管道气泡?
A:不能,因为缩小 Batch size 会推高长尾延迟,整体吞吐下降
1.3. 端到端延迟
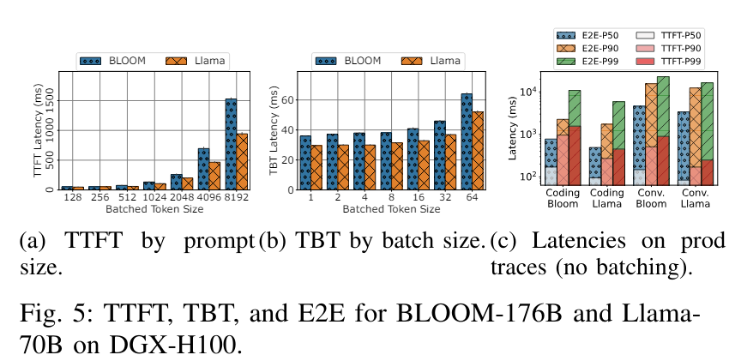
TTFT(Time To First Token):首 token 计算的耗时和首 token 长度成线性关系(几乎)
TBT(Time Between Token):batch size 对 TBT 影响很大小(单token计算耗时),当 batch size = 64 时,TBT 变化是 < 2的
E2E:大部分耗时,不管是p50,还是p99,词生成阶段的耗时是最大的
洞察3:对于大多数请求,大部分 E2E 时间都花费在词符生成阶段。This holds true even for the coding trace, where prompt sizes are large and generated tokens few ??对 coding 来说,输出的 token 很少,为什么端到端的延迟,耗时还是在词生成阶段。
1.4. 吞吐
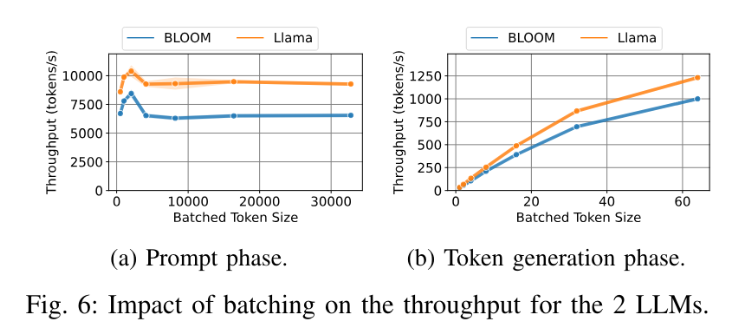
首 token 计算阶段:当 token = 2048 时,吞吐是最大的,一旦超过 2048,吞吐开始下降,再大之后,维持一个不变的水平。这个不能理解,什么原因??词生成阶段:吞吐随着 batch size 线性增长,直到 OOM
洞察4:
- 首 token 计算阶段:应该限制批处理,以实现最佳性能
- 词生成阶段:batch 应该越大越好,没有任何缺点
1.5. 内存使用率
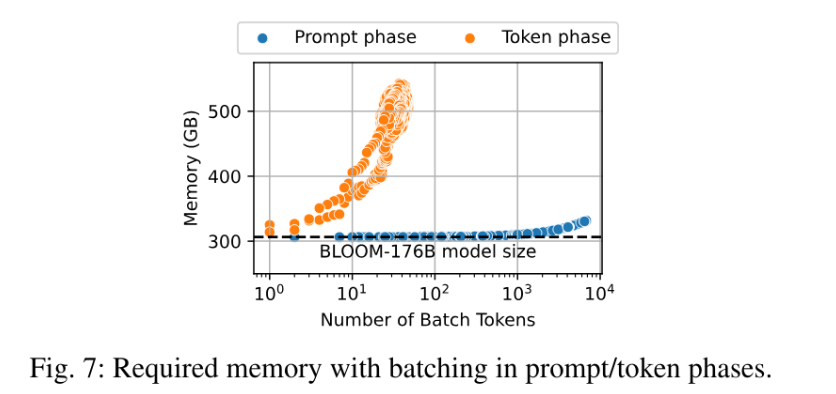
这个我还不能理解,kv cache = 4blh(s+n) ,即使是提示词阶段,显存占用也是和 token 长度成正比的?
1.6. 功耗
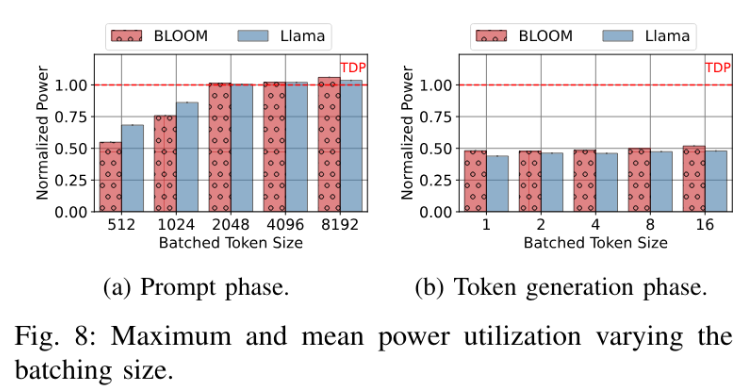
提示阶段:计算密集型,功耗随着 token 数量线性增长词生成阶段:内存密集型,token 基本不变 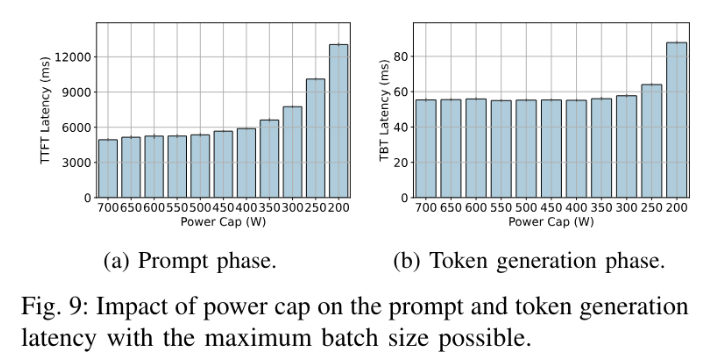
限制功率对提示阶段的性能影响很大,但是对词生成阶段基本没什么影响
1.7. GPU 硬件变化
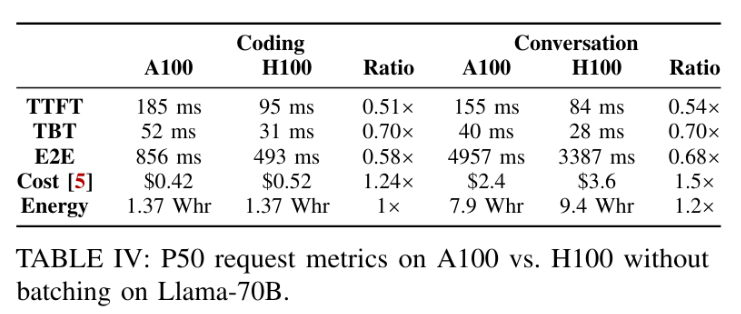
洞察:生成阶段可以在更便宜、较低的最大性能硬件上运行,以获得更好的 Perf/W 和 Perf/$ 效率。
2. 论文的核心价值
上面那么多洞察,其实最关键的是2个:
- 推理的提示词阶段和词生成阶段,有截然不同的计算特征
- 批处理利用率低表明,由于请求的速率和seq长度都会符合一定的分布,也就是非匀速的,除非在任意一个请求推理结束之后,有一个新的请求能立即接上,否则都会导致很多管道在某个时刻,是处于空闲状态的,这就是管道气泡
如下图:
- 2个GPU,bs = 2,总共4个管道,可以同时处理4个请求
- 管道只有3个状态:
- 蓝色表示prompt计算
- 黄色表示在做词生成,深黄色表示词生成被prompt计算压制了
- 白色表示空闲,也就是管道气泡,
这里会存在2个关键的问题:
- 碎片:由于管道气泡的存在(请求的速率和seq长度分布决定了气泡是必然存在的),导致了大量的碎片(也就是管道气泡),而且无法缩小 bs 大小来解决,因为缩小bs会推高长尾延迟
- 局部均衡:prompt 和 词生成跑在同一个GPU上,推高了请求的处理时间,但是这个时候是有其他空闲的GPU的,没用利用起来
池化,正是解决这个2个问题的重要思路把 prompt 计算和词生成拆成2个阶段,有2个好处:
- 减少 prompt 计算对词生成阶段的影响,过大的 tbt 会导致请求的处理时间变长
- 用不同的机器来执行,有助于把小碎片聚合成大的碎片,然后就能缩小 batch size 了,论文里的 HPA 扩缩容就是在解决这个问题的
由于词生成阶段,对计算不敏感,因而还可以用更廉价的硬件来执行,一举三得
3. 系统架构
3个资源池:
- 提示词资源池:所有机器只负责提示词计算
- 词生成资源池:所有机器只负责词生成
- 混合池:都包括
2个调度器:
- 集群调度器 CLS
- 请求路由:每个请求来的时候,分配一对机器,用于提示词计算和词生成,调度约束是,传输延迟最低。因为要传输 kv cache
- pool 是虚拟的,会根据请求的 token 分布和速率,动态调整
- 机器调度器 MLS
- FCFS 队列,控制提示词机器的token批处理数量,以及词生成机器的batch size
- 在混合池里面,为了保证 TTFT,提示词计算可以抢占词生成计算
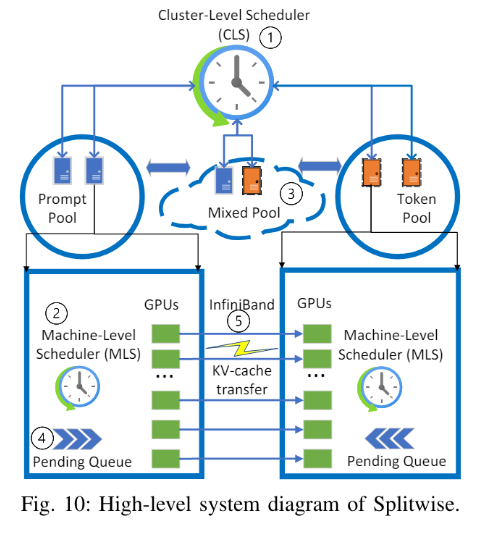
3.1. KV cache 传输优化
https://www.cnblogs.com/upyun/p/17817417.html
逐层传输,每一层计算完,就立即开始传输
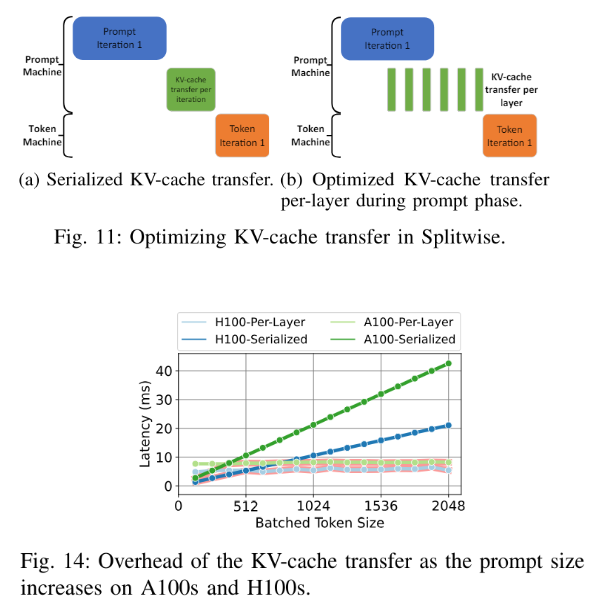
H100 大概延迟是 A100 的一半
4. 收益空间评估
4.1. 系统约束
xx