https://arxiv.org/pdf/2311.18677
https://yiyibooks.cn/arxiv/2311.18677v2/index.html
论文的核心思想:不管是 Ocra、还是 ExeGPT、还是 SplitWise,论文都提到一些关键的特点,整个推理可以分为2部分,提示阶段(首token计算阶段)和词生成,这2个阶段的负载类型是截然不同的,对算力的要求也不一样,因此,通过拆分这2阶段的计算,未来资源池里面,一部分机器用来跑首 token 计算,一部分机器用来跑词生成,通过这个方式,整个推理的吞吐提升了2倍左右
1. 论文的一些洞察
1.1. 【关键】提示阶段和词生成阶段的token分布

由于编码服务的常见情况只需要在用户键入时在程序中生成接下来的几个单词,因此输出词符的中位数为 13 个标记。另一方面,对话服务几乎呈双峰分布,生成的 Token 中位数为 129 个。洞察1:不同的推理服务可能具有截然不同的token数量分布(提示阶段、词生成阶段)
1.2. 【关键】批处理利用率
batch size = 30,但不代表每时每刻都有 30 个请求在处理,实际情况有很多管道气泡 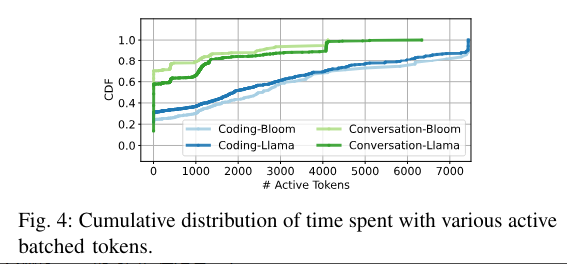
如果一个请求,在做词生成,那标记为1个活跃的token。上面这个图就是 GPU 活跃 token 数量的一个累计分布函数从这个图可以看出:
- 对 chat 来说:GPU 大概有 60% 的时间,在处理 < 20 的 token。
- 对于 code 来说:这个情况更差,大概有 30% 的时间,在处理 1 个 token
也就是说,GPU 实际运行过程中,是有非常多管道气泡的。比如 batch size 是 30,但是还是有很多时间,只有1个token在处理
推测:
Q:为什么会出现这个问题?
A:由于请求和 seq 长度存在一定的分布,所以必然会存在很多时刻,很多流水线是处于 “短暂” 的空闲的,这种空闲的时间片,就是管道气泡
Q:能不能通过缩小 Batch size 来降低管道气泡?
A:不能,因为缩小 Batch size 会推高长尾延迟,整体吞吐下降