Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache
1. 问题
模型的架构:
- QKV Linear layer
- Multi-Head Self-Attention Mechanism, or the attention module
- FNN,Feed-Forward Neural Network
超长文推理的挑战,2k -> 256k ?
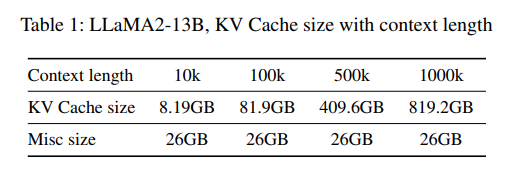
有2个:
- 不同的层对显存的需求差异很大(注意力层的显存和输入输出是成比例的,但是其他层不是),这就限制了并行的效率(类似木桶效应??)
- KV cache 的大小不可预估,显存容量不可规划
这2个问题,最终也极大的限制了超长文推理的效果