阿里云的 gpu sharing 只是实现了资源的按需分配和调度,并没有解决算力 & 显存隔离的问题
基于k8s原生的Scheduler Extender、Extended Resource、DevicePlugin机制来实现
提供2个接口:
- aliyun.com/gpu-mem: 单位从 number of GPUs 变更为 amount of GPU memory in MiB,如果一个Node有多个GPU设备,这里计算的是总的GPU Memory
- aliyun.com/gpu-count:对应于Node上的GPU 设备的数目
整体架构:
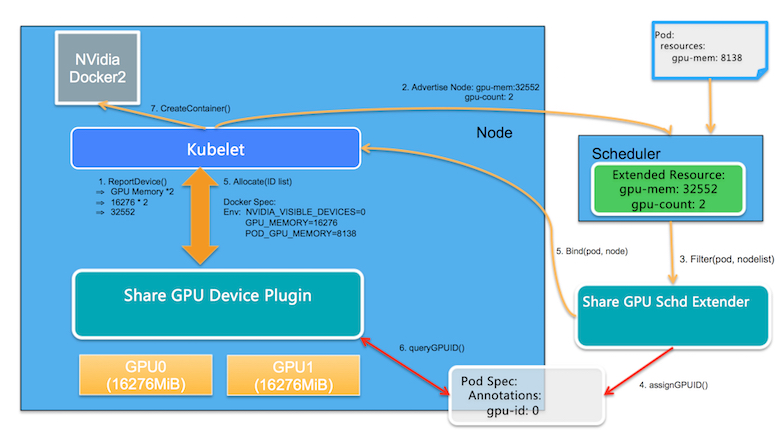
核心组件:
- GPU Share Schd Extender:基于k8s scheduler extender机制,作用于调度过程的 Filter和 Bind阶段,用于决定某个Node上的一个GPU设备是否可以提供足够的GPU Memory,并将GPU分配的结果记录到Pod Spec 的 Annotation中
- GPU Share Device Plugin:基于k8s device plugin机制,根据GPU Share Scheduler Extender记录在Pod Spec的Annotation,实现GPU 设备的 Allocation。