摘要
原文:https://arxiv.org/pdf/2202.07848.pdf
Singularity,微软的全局分布式调度服务,用于高效可靠地执行深度学习训练和推理工作负载。Singularity 的核心是一种新颖的、负载感知的调度器,它可以透明地抢占深度学习工作负载以及进行弹性伸缩,在不影响AI加速器(如 GPU、FPGA)的正确性和性能的前提下,提高利用率。
Singularity中的所有作业默认都是可抢占、可迁移、可动态调整(弹性)大小的:一个运行的作业可以动态透明地:
(a) 被抢占并迁移到不同的节点、集群、数据中心或区域,并从执行被抢占的位置恢复;
(b) 在给定类型的不同加速器上弹性伸缩resize;
我们的机制是透明的,因为它们不需要用户对代码做任何更改,也不需要使用任何可能限制灵活性的自定义库。此外,我们的方法显著提高了深度学习工作负载的可靠性。
结果表明,Singularity 提高了系统的效率和可靠性,对稳态性能的影响可以忽略不计。而且,Singularity 的设计与 DNN 架构无关,可以处理各种并行策略(例如,数据/管道/模型并行)。
1. 简介
Singularity 核心实现了 AI 任务的可抢占、可迁移、可动态调整,并且该实现与模型架构无关、与模型训练的并行策略无关,可以认为做到了用户无感。
1.1. 设计目标
Singularity 为了最大化整个集群的吞吐量,采用以下设计原则:
- 不闲置资源:Singularity 将整个加速器集群视为单个逻辑共享集群,并避免任何资源碎片化或静态容量预留。Singularity 适时调度使用全球范围内的任何空闲资源,跨集群、AZ和工作负载边界(训练与推理)。
- 提供作业级别的 SLA:在适时使用空闲容量的同时,Singularity 通过遵守作业级别的 SLA 来提供隔离。例如,当推理作业的负载增加时,Singularity 通过弹性缩小或抢占训练作业来释放容量。
- 故障弹性恢复:DNN 训练作业运行时间长达数小时、数天甚至数周,因此从头开始成本损失巨大。在 Singularity 中,作业从它们被抢占的地方恢复,从而将故障重启成本最小化。
1.2. 关健机制
为实现上面的目标,整个 Singularity 系统的底层由两大重要的机制来支撑。它们分别是:
1) 抢占和迁移机制:Singularity 可以透明地设置检查点、抢占和迁移节点间甚至跨集群和区域的所有 DNN 作业。检查点是通过高效的的同步屏障 (synchronization barrier) 来实现分布式作业的所有参与者之间分布式状态的 一致性切分 (consistent cut)。
2) 伸缩和弹性机制:Singularity 使所有工作能够使用可变数量的 AI 加速器,以透明的方式 动态地、弹性地 伸缩资源。
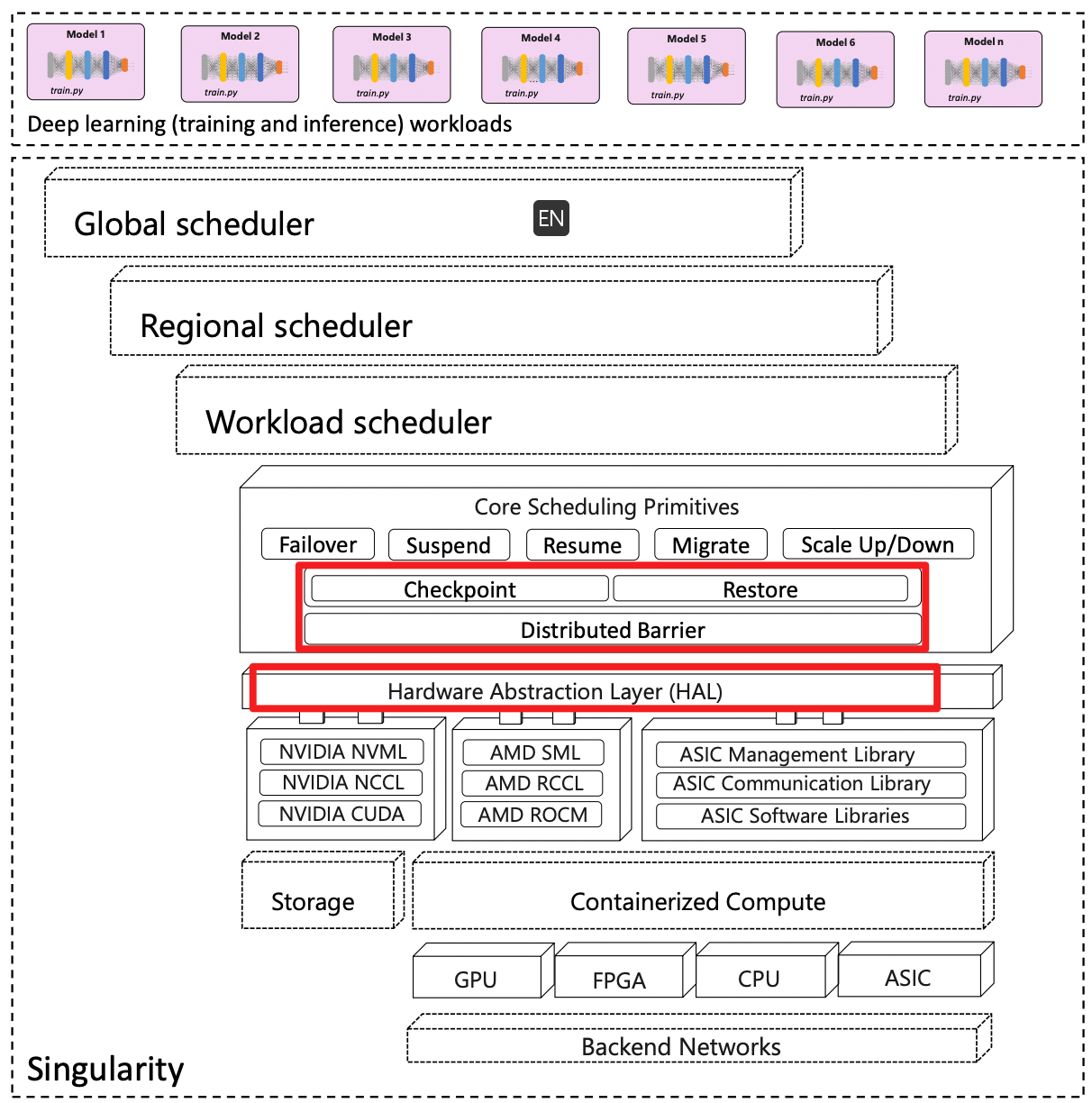
Singularity 系统架构
- 这里涵盖了所有的 AI 算力,包括 GPU、FPGA、CPU、ASIC 等不同的硬件形态。
- 所有的算力资源都被容器化了
- 硬件抽象层(HAL)竟然 在一层基础软件之上,这层基础软件包括 NVML、NCCL、CUDA,也就是设备管理、设备通信、设备计算这三类功能。
- 硬件抽象层这里的 CUDA 指的是 CUDA Driver API f. 核心调度原语。高层原语包括:Failover、Suspend、Resume、Migrate、Scale Up/Down ,底层原语包括:Checkpoint、Restore、Distributed Barrier 。