autopilot 算是 google 今年混部领域最重磅的论文了吧
论文原址:https://dl.acm.org/doi/pdf/10.1145/3342195.3387524
在传统的数据中心里,资源超售最简单的方式就是把闲置资源回收再分配,total = total – allocated + reclaim
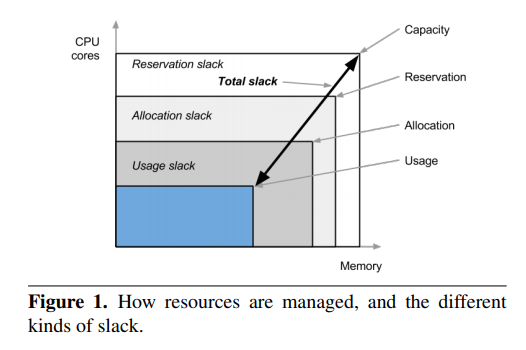
有时候,业务为了应对峰值流量(特别是互联网服务这种有明显流量特征的),都会购买多一些冗余资源。但是这些冗余资源会因为各种原因,不是那么准确。比如流量随着时间流逝会逐渐发生变化、或者用户过于焦虑
用户填的Quota永远都是不准的
这会带来一些问题:
- 集群资源浪费,由于Quota不准,导致机器资源被大量闲置和浪费。比如 Quota 分配出去了100c,但实际使用了10c
- 集群负载不均衡,同样两个机器,分配率一样,但是实际使用差别很大,对混部性能的影响就不一样
为了解决这个问题,google设计了autopilot,尝试通过自动的校准用户的 Quota,实现一定程度的超售,降低成本
autopilot 的核心思路是 vertical scaling,通过一些机器学习等技术,预测资源的合理水位,然后调整 CPU/memory limites。通过这种方法,google 将job的资源slack从46%缩小到了23%,极大的节省了资源浪费
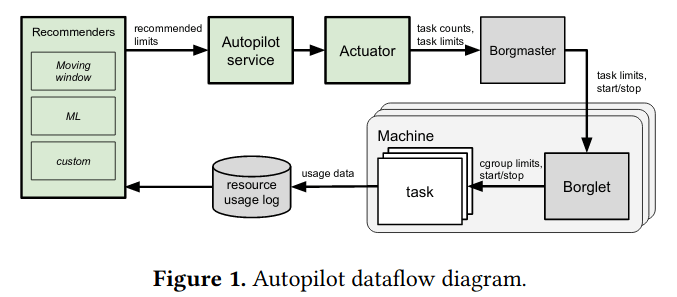
vertical scaling 最关键的地方就在于如何准确的预测资源水位,因为一旦预测不准确,会影响 Qos,CPU可能还好,内存如果预测不准,会触发OOM,这种行为不可接受
为了解决这个问题,autopilot 用了两个技术:
- 滑动窗口算法 Moving window recommenders
- 增强学习 Reinforcement learning recommenders
1. 滑动窗口算法 Moving window recommenders
如上图所示,autopilot 会长期通过 resource usage log 收集 job 运行时的资源使用数据,滑动窗口算法的作用就是根据一个窗口期内的历史数据,加权预测资源的合理limits
r_i[\tau] 表示 per-task 的 CPU/MEM 资源使用,每秒1个采样点
s_i[t] 将 r_i[\tau] 的数据按照5分钟聚合,仍然是 per-task 级别的数据
s[t] 将 s_i[t] 的数据按照 job 级别汇聚,另外job级别的汇聚,是将 per-task 的数据直接聚合,而不会单独考虑每个 task(比如单个 task 的峰值会被抹平)
1)指数衰减
对于历史数据,权重是这么设计的
w[\tau] = 2^{-\tau/t_{1/2}}其中\tau是数据的age,数据越久远,权重衰减的越快。另一个核心概念是t_{1/2},这是半衰期,对于 CPU 是12小时,内存是 48 小时。这个很好理解,通常在线流量,CPU由于天级别存在波峰波谷,但内存是常驻的,很少会发生天级别内的变化
2)峰值预测
基于当前的历史数据, per-job 级别的峰值利用率可以这么计算:
S_{max}[t] = max_{\tau \in {t-(N-1),...,t}} \{b[j]:s[\tau][j]>0\}简单来说,就是取最近N个样本的最大值
3)均值预测
均值的计算就需要开始考虑对历史数据加权了
S_{avg}[t] = \frac {\sum^{\infty}_{\tau = 0} w[\tau]\overline{s[t-\tau]}}{\sum^{N}_{\tau=0}w[\tau]}简单来说,就是加权平均
4)j-%ile 分位值预测
算法是 h[t][k] = b[k] * \sum^{\infty}_{\tau=0} w[\tau] * s[t-\tau][k]
简单来说,也是所有历史数据的 j-%ile 分位值加权平均
另外一个很有意思的地方就是 autopilot 里怎么存历史数据的,因为要对所有的 task 和 job 记录这种原始数据,假如每秒一个点,1000w个 job,1亿个容器,这个信息量非常大。autopilot 用了一种很巧妙的方式,它不存每一个采样点的数据,而是用了一种Bucket的方式,比如 CPU,分了400个bucket,每个bucket代表0.25个百分点,采样点属于哪个bucket就落在对应的计数器上+1,最终不管累计多少,维护一个 job 或者 task,只需要 400 * sizeof(int) 内存即可
最后,论文中给了一些预测的经验
对于CPU资源:
- batch jobs:使用S_{avg}来作为预测值,离线是重吞吐的,平均值足以
- serving jobs:使用S_{p95}等分位值,因为在线服务是重延迟的,对长尾很关注
对于内存资源:
- 对那些 OOM 容忍度低的,取p98分位值
- 对OOM完全无法容忍的,取max值
- 其他的大部分,取 max(p60, 0.5max)
2. 增强学习 reinforcement learning
autopilot 使用了一些增强学习来提高预测的准确率
哇哦,赞一个