论文原址:https://dl.acm.org/doi/pdf/10.1145/3342195.3387517
这篇论文主要是分析了google内部8个集群的workload数据,并和2011年(1个集群)的数据集做了一些对比,以此来跟踪数据中心这几年的workload变化
相较于2011年的workload数据,可以发现,无论是资源模型、负载分布、混部密度、系统架构,等,都有很大的变化。这里面的很多内容和想法,和我们过去做过的还有正在做的,都不谋而合
1. 资源模型
2011年的时候,google的资源模型只有4个优先级,分别是:
- Free tier:免费资源,基本上不承诺任何SLA,通常是研发用来跑一些测试任务
- Best-effort Batch (beb) tier:同样不承诺SLA,低优先级资源,一般用来跑离线任务
- Production tier:生产级别,承诺SLA,一般用来托管在线服务,比如以下 long runing service
- Monitoring tier:监控级别,具有最高级别的SLA,用来运行数据中心的基础系统
2019年的时候,发生了比较多的变化,主要有2点
首先是新增了一种优先级,Mid-tier,同时承诺较低的SLA,让用户在beb和production之间多了一种选择。据我所知,production-tier承诺的SLA是99%,mid-tier承诺的SLA是93%。google对SLI的定义是,同一时刻同时提供服务的副本数,同时会考虑多级故障域可用性
其次是优先级的定义更细粒度了,2011年的时候还是按照band来区分,2019年的时候变成了一个range,比如[119,120] 代表 mid-tier。如果更细心一点的可以看出来,上述5个优先级的range定义并非是连续的,有很多gap所代表的含义,论文并没有讲。其实google内部是有很多专用集群的,比如可能存在一个集群,专门用来托管存储服务,另外,也有一些历史遗留的独占集群
2. 负载分布和规模
google的负载分布很奇怪,其实也不奇怪,比如论文里说的:
the workload exhibits an extremely heavy-tailed distribution where the top 1% of jobs consume over 99% of resources;
你把这句话反过来理解就是:99%的作业只消耗了1%的资源。这一点真是充分暴露了google基础架构的牛逼之处,资源弹性已经做到了极致。这99%的作业绝大多数都是一些研发人员的测试job,也就是说,在google内部,任何人都可以很容易的使用云上的资源
另一个重要的发现的,从11年到19年,google大量的job从free-tier提到了beb优先级,我猜主要原因是混部密度增大,这个后面会讲,混部密度增大会加剧资源的不稳定程度,为了可以获得更好的稳定性,业务从free-tier迁移到beb是很合理的现象
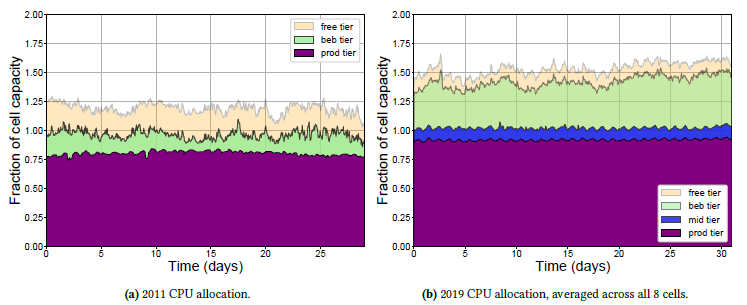
负载规模也发生了比较大的变化
The scheduling rate is higher (§6): the job submission rate is 3.7× higher than in 2011, and the number
of tasks needing to be scheduled has increased by a factor of 7, even though the sizes of the 2019 cells are comparable to the 2011 cell. Despite this, the time the scheduler takes to find places to host the tasks is largely unchanged
job提交速度翻了3.7倍,调度队列pending数翻了7倍。这些变化,从上面的分配率就能看得出来
3. 混部密度
混部密度增大是这过去8年最大的变化了,google数据中心的平均利用率达到了惊人的60%。这个数字对我们这些搞技术的人来说真是一种鼓舞。可以参考下15年的时候,google、aws、facebook、twitter 等数据中心的利用率,那会大多数还只是30%多
1)资源实际使用变化
第一个变化是是CPU和内存的使用变化,可以看到这8个集群的:
- 平均CPU利用率从11年的30%~40%涨到了19年的52%~62%
- 平均内存利用率从11年的40%涨到了19年的60%
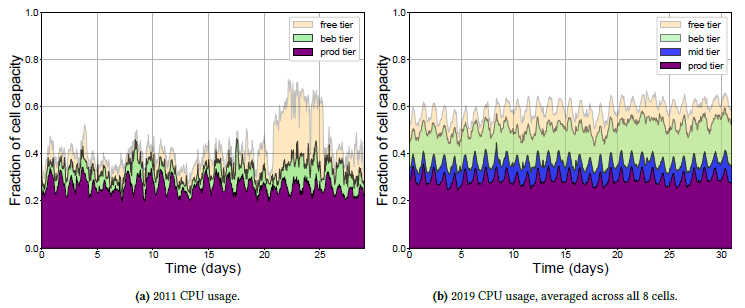
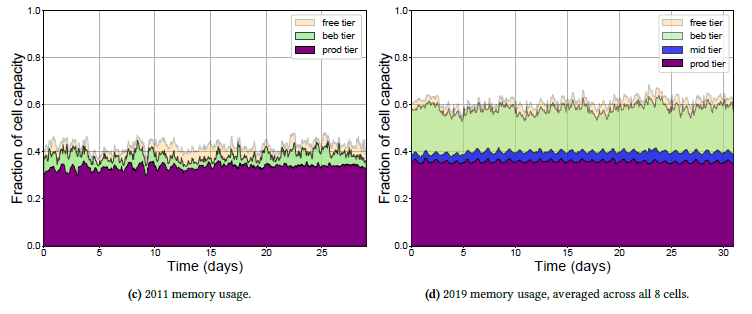
而且有一个很关键的地方是,CPU、内存的比例非常均衡,基本上都是1比1,说明调度算法处理的很好,基本上没有碎片化的问题
另外,上面这个数据是8个集群的平均值,论文中还单独分析了每个集群的资源使用率,有些集群CPU利用率达到了90%,这个集群的prod资源使用比较低。CPU利用率超过70%一定会有超线程干扰的问题,利用率上去了之后,CPU执行指令的延迟会变的非常大,这个问题一直是混部的难题
不过超线程问题,本身是core粒度的,阿里巴巴我记得有做noice clean的内核调度优化。所以也不是说这个问题无解,google能把线上集群压到这个程度,至少可以证明技术上是可行的
2)资源分配率
分配率从11年到19年也有非常大的变化:
- CPU分配率从11年的125%提升到19年的150%
- 内存分配率从11年的90%提升到了19年的150%
可见内存超发非常保守,不过11年的时候google的技术应该是最超前的,不但06年就开源了cgroup这些技术,而且整个基础架构的顶层设计做的很好,比如存储计算分离。内存超发我理解应该不会难倒google

还有一个比较有意思的发现就是,production的cpu分配率已经达到了90%,这个还是很难得的,通常production的资源不会超售给同等优先级的服务使用,如果不超售,要达到这个分配率,对调度的碎片优化是一个很大的挑战
4. Autopilot
google以autopilot命名,足以证明这个系统的重要性了,集群管理的无人驾驶系统
autopilot 主要的目的是要降低资源的Request和Used之间的slack,因为很多时候用户填资源都是瞎填的,比如申请了100g内存,但是常态下只用到10g不到
所以autopilot要做的事情就是,如何更精准的预测用户的资源需求,并以此来指导集群调度
autopilot已经单独发论文了,所以这部分后面我再详细描述
实际上 google 的 borg 一直有一个类似的很牛逼的功能,就是用户提交 job 的时候,是可以通过 auto 关键字来申请资源的,用户无需明确指定资源需求,让borg来自动给你分配