论文原址:https://www.usenix.org/system/files/conference/atc18/atc18-iorgulescu.pdf
演讲PPT:https://www.usenix.org/sites/default/files/conference/protected-files/atc18_slides_iorgulescu.pdf
这是微软在18年 usenix 会议上公开的一篇混部论文。这也是微软在混部这个领域公开的为数不多的论文之一。论文中描述了bing业务(非公有云)如何通过在离线混部 + CPU Blind Isolation 这个技术,将 indexserver 集群的利用率从21%提升到66%的过程
其中最关键的,还是 CPU Blind Isolation 这个技术,很有意思。
1)首先,indexserver 的架构本身,决定了它对长尾延迟是非常敏感的
- a complex layered architecture – hard to model or predict, since responses are computed in parallel and then aggregated.
- short tail latency – any layer can severely impact query response times
- highly bursty nature – the service frequently spawns a large number of workers in a short period of time (order of microseconds).
而在 indexserver + 离线 混部这个场景里,影响长尾延迟最大的因素的内核的 CFS 调度延迟。Indexserver 会经常由于突发性的请求得不到 CPU 的及时处理而产生严重的长尾
2)修改内核 CFS 调度算法?
内核的 CFS 调度算法,由于过度追求公平性。不适合混部场景。但是云计算技术,混部超售技术发展了那么多年,其实内核的 CFS 算法并没有太多变化
因为面向云、混部、特定的超售场景而设计的调度算法,不是一个通用的调度算法
另外,修改内核的成本太高:一个是稳定性问题,容易触发内核crash;二是基础设施的迭代周期非常漫长(一个集群的内核升级通常以年为周期);三是由一以及二带来的研发效率问题
3)用户态 CPU Blind Isolation
简单来说就是 cpuset 绑核,但是怎么绑,很有讲究
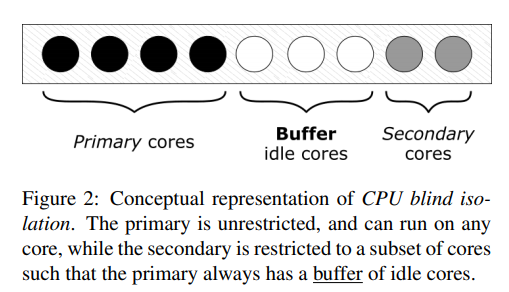
Primary Cores 用来跑 indexserver 服务,Secondary cores 跑离线,并且为了让 indexserver 新启动的线程能够立即得到 CPU 运行时间,还预留了一部分的 Buffer idle cores
其中 Buffer idle cores 的计算并不是根据利用率来计算了,为了得到真正意义上的 idle core,他们通过一个内核系统调用,来查询当前完完全全处于 idle 状态的 CPU 列表
We consider a core to be idle if the idle thread is running there。The Windows scheduler keeps track of idle cores and provides this information through a system call. This system call returns a bit mask with the bits corresponding to the idle CPUs’ ids set
有一个问题,这种方案能够使得在线业务CPU利用率最大化,但是离线业务只能绑在Secondary cores上,那么在线业务空闲时离线业务CPU无法最大化利用CPU
微软的indexserver是延迟非常敏感的,所以他们设计上就是离线不能和在线跑到同一个cpu上的