参考 mit 课程:https://web.mit.edu/6.034/wwwbob/svm.pdf
SVM 是机器学习领域非常流行的一个分类算法。他的前身其实就是感知机,想了解感知机原理的可以简单看我之前写的文章
传统感知机是有很多局限性的问题的,比如解决不了线性不可分的问题,比如泛化能力不强因为你可以找到N个解,但是不知道哪一个是最好的。SVM 就能很好的解决这些问题。
1. 支持向量
搞清楚什么是支持向量是了解SVM的前提。但是这里只能抽象的讲解,了解后面的内容,会加深你对支持向量的理解
在一个分类问题里,我们可能会有多个解,比如:
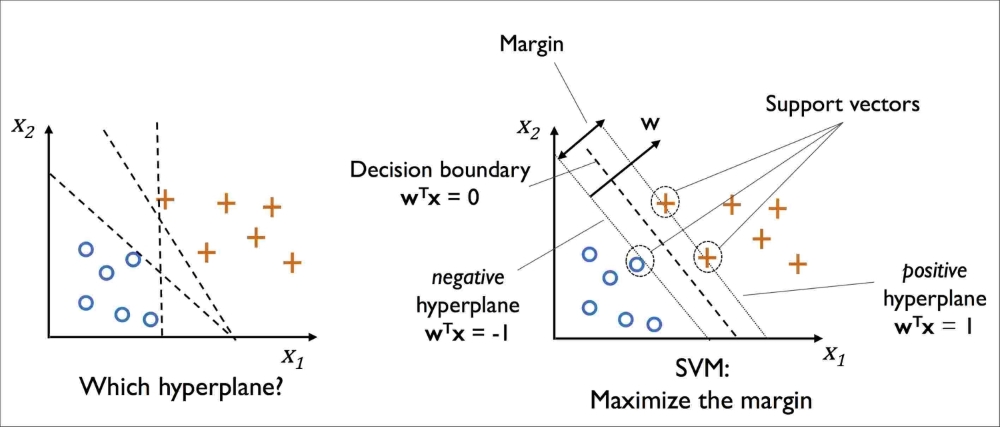
但是取哪个是最好的呢?直觉告诉我们,选能让样本分割的最远的超平面,这个就是 SVM 的做法,最大间隔化(后面会讲形式化的定义和推导)。SVM使用两个间隔最大的超平面,将所有数据完美分割在两边。
所以数学上,只需要一个超平面 + 间隔,就能形成一个决策边界,那些依附在决策边界上的点,就叫支持向量。为什么要给这些点起一个专有的名词?因为定义这个超平面只需要用到这些点,而其他远距离的点都是多余的。所以通常在一个2维空间上,最少只需要3个点,就能定义这个超平面